


Introduction
Artificial Intelligence has transformed the way machines perceive and interact with the world. From autonomous vehicles to smart surveillance systems, object detection models play a crucial role in enabling machines to recognize and understand visual data. Among the most influential families of object detection algorithms is the YOLO series, which stands for “You Only Look Once.”
Over the years, YOLO models have become synonymous with speed, efficiency, and accuracy. However, traditional YOLO systems were limited to detecting predefined object categories. If a model was not trained on a specific object class, it could not recognize it.
This limitation led researchers to develop more advanced solutions capable of recognizing unseen objects using textual descriptions. One of the most exciting breakthroughs in this field is the YOLO-World model — an open-vocabulary real-time object detection framework that bridges the gap between vision and language understanding.
YOLO-World combines the speed of the YOLO family with the flexibility of vision-language models, enabling AI systems to detect virtually any object described by text prompts without requiring retraining.
In this comprehensive guide, we will explore everything about YOLO-World, including its architecture, working mechanism, advantages, challenges, use cases, and future potential.
What Is YOLO-World?
YOLO-World is an advanced open-vocabulary object detection model designed to perform real-time detection of objects using natural language prompts.
Unlike conventional object detection systems that can only recognize categories present in their training datasets, YOLO-World can identify unseen objects by understanding textual descriptions. This capability is known as open-vocabulary detection.
For example, instead of being restricted to labels such as:
- Person
- Car
- Dog
- Bicycle
YOLO-World can detect:
- Red electric scooter
- Construction worker wearing helmet
- Blue ceramic mug
- Drone with camera
- Golden retriever puppy
This makes the model significantly more flexible and practical for real-world AI applications.

Understanding Open-Vocabulary Object Detection
Traditional object detectors rely on fixed label sets. These systems are trained using annotated datasets containing predefined classes.
The challenge arises when new objects appear that were not part of training data.
Open-vocabulary detection solves this issue by integrating language understanding into object detection systems.
Instead of depending solely on predefined labels, the model can interpret human language descriptions and map them to visual features.
This means the model can detect unseen categories dynamically using prompts.
For example:
- “Find all laptops on the table”
- “Detect firefighters”
- “Locate orange traffic cones”
The system understands both language and image content simultaneously.
The Evolution of YOLO Models
The YOLO family has evolved significantly over time.
YOLOv1
Introduced the single-stage detection paradigm for real-time object detection.
YOLOv2 and YOLOv3
Improved accuracy, anchor boxes, and multi-scale prediction.
YOLOv4 and YOLOv5
Enhanced efficiency and deployment flexibility.
YOLOv6, YOLOv7, and YOLOv8
Focused on speed optimization, edge AI deployment, and scalability.
YOLO-World
Introduced open-vocabulary detection by integrating vision-language capabilities into the YOLO framework.
YOLO-World represents a major leap forward because it combines:
- Real-time inference
- Open-vocabulary recognition
- Vision-language alignment
- Efficient deployment
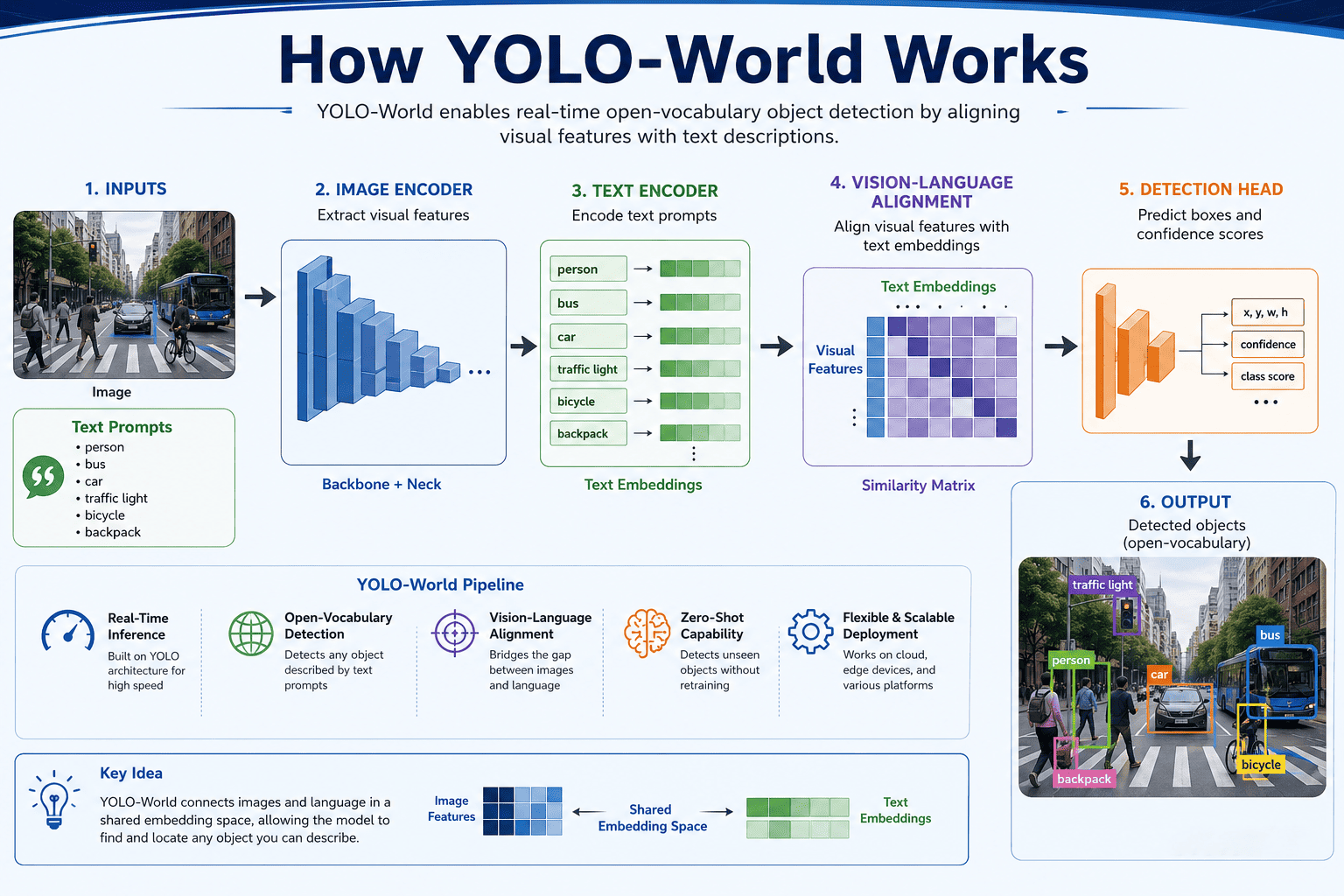
How YOLO-World Works
YOLO-World merges traditional object detection pipelines with language-aware embeddings.
The system consists of several core components:
1. Image Encoder
The image encoder extracts visual features from input images.
It identifies patterns such as:
- Shapes
- Textures
- Colors
- Object boundaries
These features are converted into numerical representations called embeddings.
2. Text Encoder
The text encoder processes textual prompts.
For example:
- “Cat”
- “Red sports car”
- “Airport luggage”
The text descriptions are transformed into semantic embeddings.
3. Vision-Language Alignment
The visual embeddings and text embeddings are aligned within a shared feature space.
This allows the model to compare image regions with textual descriptions and determine matches.
4. Detection Head
The detection head predicts:
- Bounding boxes
- Confidence scores
- Semantic similarity scores
The model outputs object locations corresponding to text prompts.
Key Features of YOLO-World
Real-Time Performance
YOLO-World maintains the high-speed inference capabilities of the YOLO family.
This enables deployment in:
- Autonomous systems
- Smart cameras
- Robotics
- Edge AI devices
Open-Vocabulary Recognition
The model can detect unseen objects without retraining.
Users simply provide new prompts.
Zero-Shot Detection
YOLO-World performs zero-shot learning by recognizing categories absent from training datasets.
Flexible Deployment
The model supports:
- Cloud environments
- Edge devices
- Embedded systems
- GPUs
- Industrial AI pipelines
Language-Guided Detection
Text prompts enable highly customized object detection.
Examples include:
- “Damaged package”
- “People wearing masks”
- “Electric vehicles”
YOLO-World Architecture Explained
The architecture of YOLO-World is designed to balance speed and semantic understanding.
Backbone Network
The backbone extracts image features.
Common backbones include:
- CSPDarknet
- EfficientNet
- Vision Transformers
Neck Network
The neck combines features from multiple scales.
This improves detection for:
- Small objects
- Large objects
- Complex scenes
Multi-Modal Fusion Layer
This is the core innovation.
The fusion layer integrates:
- Visual embeddings
- Text embeddings
The model learns semantic relationships between language and visual regions.
Detection Head
The final stage predicts object localization and matching scores.
Advantages of YOLO-World
1. Unlimited Object Categories
Traditional models are limited by training labels.
YOLO-World can recognize virtually any object described in text.
2. Reduced Retraining Costs
Organizations no longer need to retrain models for every new category.
This dramatically reduces:
- Annotation costs
- Training time
- Infrastructure expenses
3. Better Scalability
YOLO-World scales efficiently for enterprise AI systems.
4. Enhanced User Interaction
Users interact naturally using language prompts.
5. Improved Generalization
The model generalizes better to unseen environments.
YOLO-World vs Traditional YOLO Models
| Feature | Traditional YOLO | YOLO-World |
|---|---|---|
| Fixed Categories | Yes | No |
| Open-Vocabulary | No | Yes |
| Text Prompt Support | No | Yes |
| Zero-Shot Detection | Limited | Strong |
| Real-Time Speed | Excellent | Excellent |
| Language Understanding | None | Advanced |
YOLO-World vs CLIP-Based Detection Models
YOLO-World is often compared with CLIP-powered systems.
CLIP-Based Models
CLIP excels at image-text understanding but often lacks real-time detection efficiency.
YOLO-World Advantages
YOLO-World provides:
- Faster inference
- Better localization
- Real-time object detection
- Edge deployment capabilities
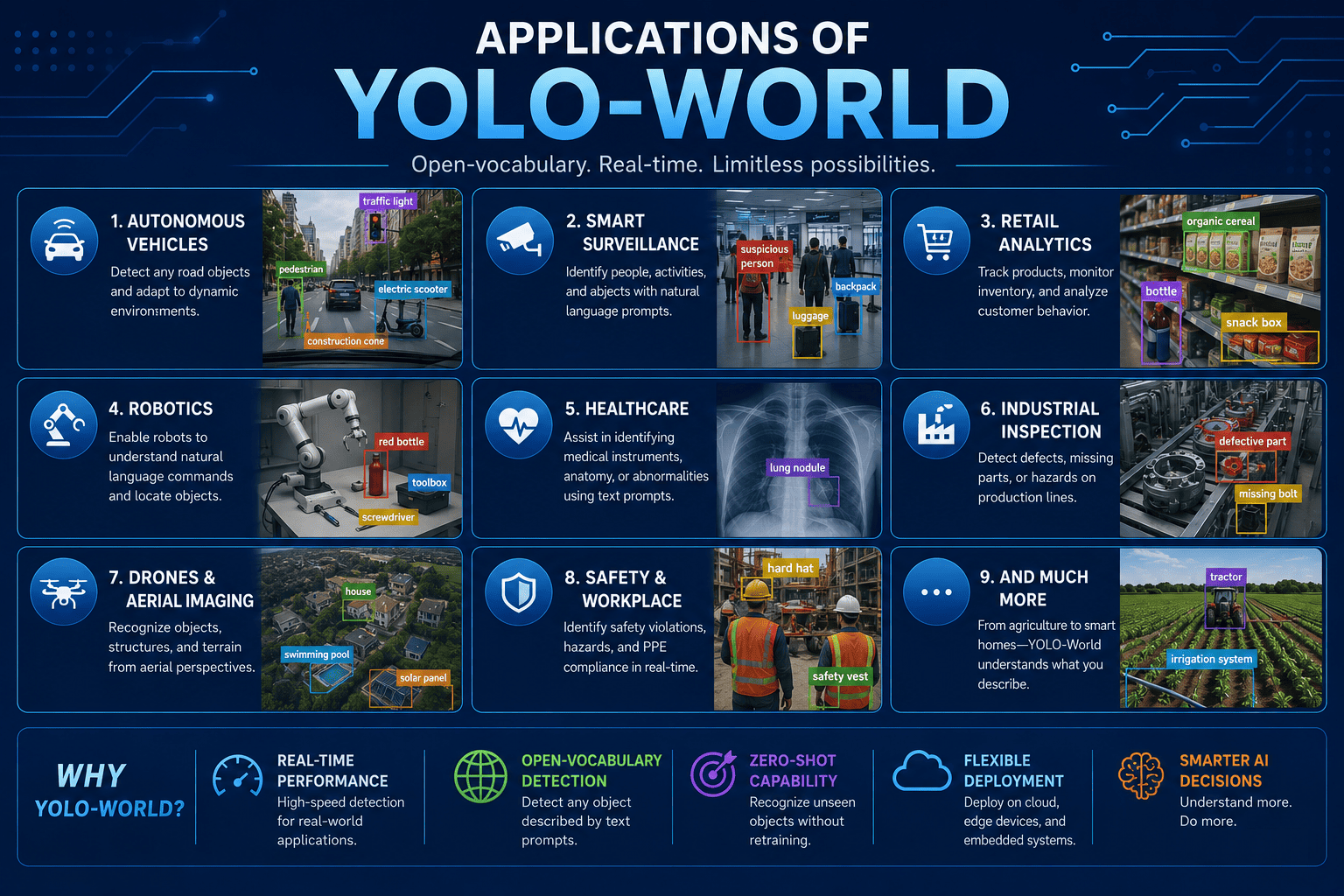
Applications of YOLO-World
Autonomous Vehicles
YOLO-World can identify unexpected road objects using text prompts.
Examples include:
- Fallen tree branches
- Electric scooters
- Construction barriers
Smart Surveillance
Security systems can detect:
- Suspicious activities
- Safety violations
- Unauthorized objects
Retail Analytics
Retailers can track:
- Product categories
- Shelf inventory
- Customer behavior
Robotics
Robots can understand flexible commands such as:
- “Pick up the red bottle”
- “Find the toolbox”
Healthcare
Medical imaging systems can assist in identifying rare visual patterns.
Industrial Inspection
Factories can detect:
- Damaged parts
- Missing components
- Safety hazards
YOLO-World for Edge AI
Edge AI deployment is becoming increasingly important.
YOLO-World supports lightweight inference suitable for:
- Drones
- IoT devices
- Smart cameras
- Mobile devices
This reduces latency and improves privacy.
Challenges of YOLO-World
Despite its impressive capabilities, YOLO-World still faces several challenges.
Semantic Ambiguity
Text prompts can sometimes be vague.
For example:
- “Bank” may refer to a riverbank or financial institution.
Fine-Grained Detection
Highly similar objects remain difficult to distinguish.
Computational Complexity
Vision-language fusion increases computational requirements.
Data Bias
Biases in training data may affect detection quality.
Training YOLO-World
Training involves combining:
- Large-scale image datasets
- Text annotations
- Contrastive learning methods
The model learns to align textual semantics with visual features.
Datasets Used in YOLO-World
Common datasets include:
- COCO
- Objects365
- LVIS
- Visual Genome
Large-scale captioned image datasets are also important.
YOLO-World and Vision-Language Models
YOLO-World is part of a broader trend in multimodal AI.
It combines ideas from:
- Object detection
- Natural language processing
- Contrastive learning
- Vision-language alignment
This makes it highly adaptable for future AI systems.
Performance Benchmarks
YOLO-World achieves impressive results in:
- Open-vocabulary benchmarks
- Real-time FPS metrics
- Zero-shot detection tasks
The model balances speed and accuracy effectively.
YOLO-World in Real-World AI Systems
Modern enterprises increasingly adopt open-vocabulary AI systems because they offer:
- Faster adaptation
- Reduced retraining
- Improved automation
- Flexible deployment
YOLO-World enables organizations to build scalable AI pipelines without constant model updates.
YOLO-World for Edge AI
Edge AI deployment is becoming increasingly important.
YOLO-World supports lightweight inference suitable for:
- Drones
- IoT devices
- Smart cameras
- Mobile devices
This reduces latency and improves privacy.
Challenges of YOLO-World
Despite its impressive capabilities, YOLO-World still faces several challenges.
Semantic Ambiguity
Text prompts can sometimes be vague.
For example:
- “Bank” may refer to a riverbank or financial institution.
Fine-Grained Detection
Highly similar objects remain difficult to distinguish.
Computational Complexity
Vision-language fusion increases computational requirements.
Data Bias
Biases in training data may affect detection quality.
Training YOLO-World
Training involves combining:
- Large-scale image datasets
- Text annotations
- Contrastive learning methods
The model learns to align textual semantics with visual features.
Datasets Used in YOLO-World
Common datasets include:
- COCO
- Objects365
- LVIS
- Visual Genome
Large-scale captioned image datasets are also important.
YOLO-World and Vision-Language Models
YOLO-World is part of a broader trend in multimodal AI.
It combines ideas from:
- Object detection
- Natural language processing
- Contrastive learning
- Vision-language alignment
This makes it highly adaptable for future AI systems.
Performance Benchmarks
YOLO-World achieves impressive results in:
- Open-vocabulary benchmarks
- Real-time FPS metrics
- Zero-shot detection tasks
The model balances speed and accuracy effectively.
YOLO-World in Real-World AI Systems
Modern enterprises increasingly adopt open-vocabulary AI systems because they offer:
- Faster adaptation
- Reduced retraining
- Improved automation
- Flexible deployment
YOLO-World enables organizations to build scalable AI pipelines without constant model updates.
Conclusion
YOLO-World is redefining the future of computer vision by introducing real-time open-vocabulary object detection.
By integrating language understanding with high-speed object detection, the model overcomes one of the biggest limitations of traditional AI systems — fixed category recognition.
From robotics and surveillance to healthcare and autonomous driving, YOLO-World unlocks new possibilities for intelligent systems capable of understanding the world more naturally.
As research continues, YOLO-World and similar multimodal AI models are expected to become foundational technologies in next-generation computer vision applications.
FAQ About YOLO-World
What is YOLO-World?
YOLO-World is an open-vocabulary real-time object detection model that combines the YOLO architecture with vision-language understanding to detect objects using text prompts.
What makes YOLO-World different from traditional YOLO models?
Traditional YOLO models can only detect predefined categories, while YOLO-World can recognize unseen objects through natural language prompts.
What is open-vocabulary object detection?
Open-vocabulary detection allows AI models to identify objects that were not explicitly included in training datasets.
Can YOLO-World perform zero-shot detection?
Yes. YOLO-World supports zero-shot detection by recognizing unseen categories using semantic language understanding.
Is YOLO-World suitable for real-time applications?
Yes. YOLO-World is optimized for real-time inference and can be deployed in robotics, surveillance, autonomous vehicles, and edge AI systems.
What are the main applications of YOLO-World?
Applications include:
- Autonomous driving
- Retail analytics
- Industrial inspection
- Smart surveillance
- Robotics
- Healthcare AI
Does YOLO-World require retraining for new objects?
No. Users can detect new objects by simply providing text descriptions.
What are the limitations of YOLO-World?
Some limitations include semantic ambiguity, computational complexity, and challenges in distinguishing highly similar objects.
Is YOLO-World better than CLIP-based object detectors?
YOLO-World often provides faster real-time detection and better localization performance while maintaining open-vocabulary capabilities.
What is the future of YOLO-World?
The future includes better multimodal reasoning, improved efficiency, video understanding, and broader enterprise AI adoption.








