


Introduction
When Meta introduced the Segment Anything Model (SAM), it didn’t just release another AI model—it redefined how we think about image segmentation.
Before SAM, segmentation models were:
- Task-specific
- Data-hungry
- Hard to generalize
SAM flipped that paradigm by introducing a foundation model for vision—a system capable of segmenting virtually anything with minimal input.
Since then, the evolution from SAM 1 → SAM 2 → SAM 3 has followed a clear trajectory:
- Static → Dynamic
- Manual → Assisted
- Reactive → Context-aware
This blog dives deep into each version, not just at a surface level—but across architecture, capabilities, limitations, and real-world impact.
What Is the Segment Anything Model (SAM)?
At its core, SAM is a promptable segmentation system.
Instead of asking:
“Can this model segment cats?”
You ask:
“Given this prompt, what object do you want?”
Supported Prompts
- Points (foreground/background)
- Bounding boxes
- Masks
- (Emerging) natural language
This flexibility is what makes SAM so powerful—it turns segmentation into an interactive and general-purpose tool.

SAM 1: The Breakthrough (2023)
SAM 1 laid the foundation for everything that followed.
Core Idea
A universal segmentation model trained on an unprecedented dataset (SA-1B).
Architecture Overview
SAM 1 consists of three main components:
- Image encoder (Vision Transformer-based)
- Prompt encoder
- Mask decoder
This modular design allows the model to:
- Understand the image globally
- Adapt to user input dynamically
- Generate precise segmentation masks
Key Features
1. Massive Training Dataset
- Over 1 billion masks
- Diverse domains:
- Natural images
- Indoor scenes
- Complex object boundaries
2. Zero-Shot Generalization
SAM 1 works across:
- Medical scans
- Satellite imagery
- Industrial datasets
…without retraining.
3. Prompt Flexibility
Users can guide segmentation with minimal effort:
- Click a point → get object
- Draw a box → isolate region
Strengths
- Extremely versatile
- High-quality segmentation
- Works out-of-the-box
- Ideal for annotation pipelines
Weaknesses
- No temporal awareness
- Requires manual interaction
- Not optimized for real-time systems
- Limited contextual reasoning
Real-World Applications
- Data labeling platforms
- Medical imaging annotation
- Creative tools (e.g., background removal)
- Preprocessing for machine learning pipelines
👉 Key Insight:
SAM 1 is a tool for humans, not an autonomous system.

SAM 2: From Images to Streaming Intelligence (2024)
SAM 2 represents a massive leap forward.
Instead of treating images independently, SAM 2 introduces:
👉 continuous visual understanding
Core Innovation: Temporal Memory
SAM 2 doesn’t just see—it remembers.
What This Enables:
- Object tracking across frames
- Consistent segmentation in video
- Reduced need for repeated prompts
Architectural Evolution
SAM 2 extends SAM 1 by adding:
- Streaming memory modules
- Frame-to-frame feature propagation
- Real-time inference optimizations
This transforms the model into something closer to a perception engine rather than a static tool.
Key Features
1. Video Segmentation
- Works across entire sequences
- Maintains object identity
2. Real-Time Interaction
- Near live processing
- Suitable for camera feeds
3. Persistent Object Tracking
- Once selected, objects stay tracked
- Handles occlusion better
Strengths
- Excellent for video workflows
- Reduces manual input
- More scalable for real-world systems
- Enables interactive AI applications
Weaknesses
- Computationally heavier
- Still relies on prompts
- Tracking drift in long videos
- Limited semantic understanding
Real-World Applications
- Video editing tools
- Autonomous driving perception
- Surveillance and monitoring
- Sports analytics
👉 Key Insight:
SAM 2 shifts from interaction → continuity.
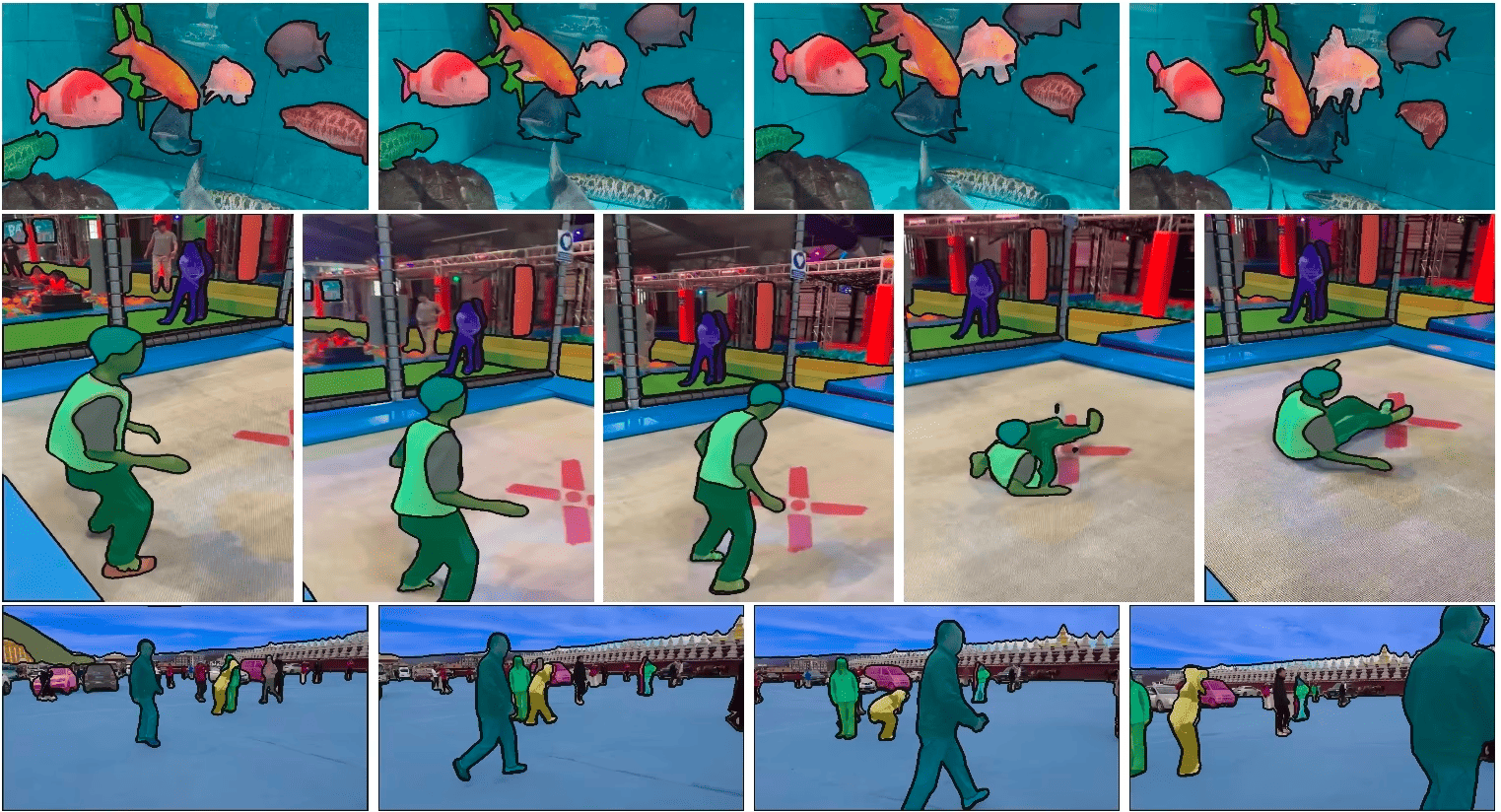
SAM 3: Toward General Visual Intelligence (2025–2026)
Unlike SAM 1 and SAM 2, SAM 3 is less of a single release and more of an evolutionary direction.
It represents the convergence of:
- Computer vision
- Language models
- Reasoning systems
Core Idea
👉 Segmentation becomes context-aware and autonomous
Key Innovations (Emerging)
1. Multimodal Prompts
Instead of clicks, you can say:
- “Segment all broken objects”
- “Highlight the main subject”
This blends segmentation with natural language understanding.
2. Semantic Awareness
SAM 3 doesn’t just segment shapes—it understands:
- Object roles
- Scene context
- Relationships
3. Reduced Human Input
- Automatic object discovery
- Prioritization of important regions
- Smart defaults
4. Integration with AI Agents
SAM 3 can act as the “eyes” of:
- Robotics systems
- Autonomous agents
- AR/VR environments
5. 3D & Spatial Understanding
Future SAM systems are expected to:
- Segment across multiple views
- Build spatial maps
- Work in immersive environments
Strengths (Projected)
- Context-driven segmentation
- Cross-modal reasoning
- Scalable to complex environments
- Minimal supervision required
Limitations (Current State)
- Still evolving rapidly
- Not standardized
- Trade-offs in performance vs intelligence
- Requires integration with larger AI systems
Real-World Applications
- Robotics and automation
- AI copilots with vision
- Smart surveillance
- Mixed reality systems
👉 Key Insight:
SAM 3 moves from seeing → understanding.
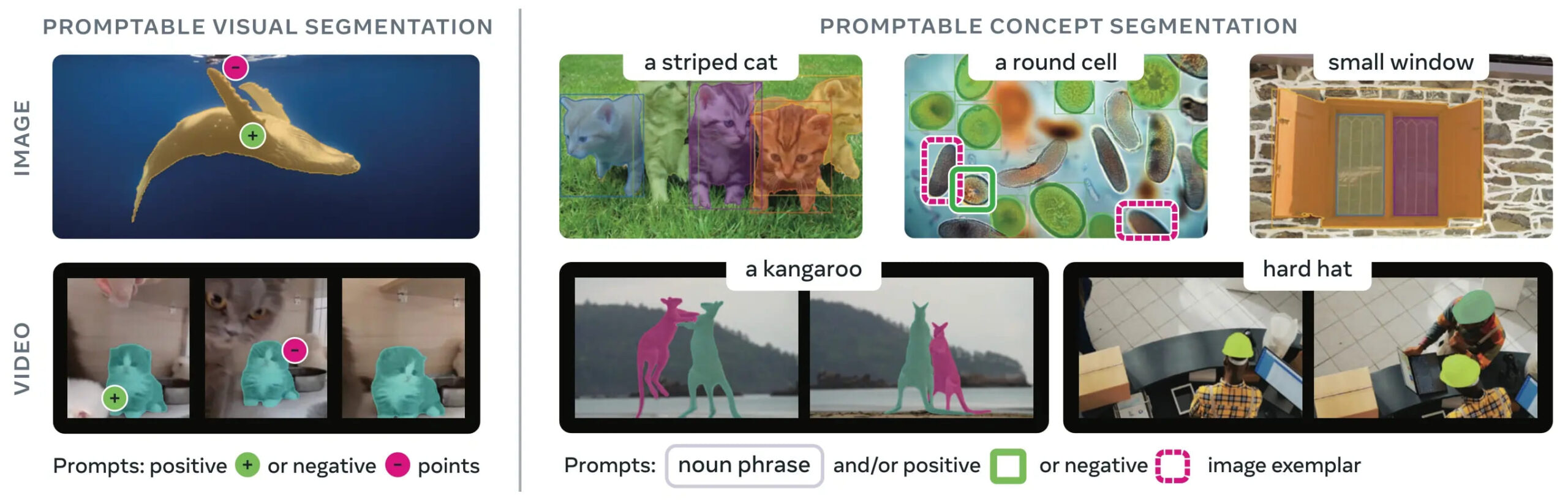
Deep Technical Comparison
1. Interaction Model
| Version | Interaction Style |
|---|---|
| SAM 1 | Manual prompts |
| SAM 2 | Prompt + tracking |
| SAM 3 | Natural language + autonomous |
2. Temporal Capabilities
| Version | Temporal Awareness |
|---|---|
| SAM 1 | None |
| SAM 2 | Frame memory |
| SAM 3 | Contextual memory |
3. Intelligence Layer
| Version | Intelligence Level |
|---|---|
| SAM 1 | Reactive |
| SAM 2 | Persistent |
| SAM 3 | Context-aware |
4. Deployment Readiness
| Version | Deployment |
|---|---|
| SAM 1 | Mature |
| SAM 2 | Production-ready (select use cases) |
| SAM 3 | Experimental / emerging |
SAM vs Traditional Segmentation Models
Before SAM, models like:
- Mask R-CNN
- U-Net
required:
- Task-specific training
- Labeled datasets
- Fine-tuning
SAM eliminates much of that by:
- Generalizing across domains
- Reducing labeling effort
- Enabling interactive workflows
👉 This is why SAM is often considered a foundation model for vision, similar to how large language models transformed NLP.
Practical Guidance: Which One Should You Use?
Use SAM 1 if:
- You need high-quality image segmentation
- You’re building annotation tools
- You want stability and simplicity
Use SAM 2 if:
- You work with video or live feeds
- You need object tracking
- You want interactive real-time systems
Watch SAM 3 if:
- You’re building next-gen AI products
- You need multimodal intelligence
- You’re working in robotics, AR, or agents
The Bigger Picture: Where This Is All Going
The evolution of SAM reflects a broader shift in AI:
Phase 1: Tools
- Assist humans
- Require input
- Limited context
Phase 2: Systems
- Handle continuous data
- Reduce manual effort
- Improve efficiency
Phase 3: Intelligence
- Understand context
- Act autonomously
- Integrate across modalities
Final Thoughts
The journey from SAM 1 to SAM 3 is not just an upgrade cycle—it’s a transformation in how machines perceive the world.
- SAM 1: A powerful segmentation tool
- SAM 2: A real-time perception system
- SAM 3: A step toward visual intelligence
As AI continues to evolve, segmentation will no longer be a standalone task—it will become a core component of intelligent systems that see, understand, and act.
Frequently Asked Questions (FAQ)
1. What is the Segment Anything Model (SAM)?
The Segment Anything Model (SAM) is a general-purpose AI model developed by Meta that can segment (separate) objects in images or videos based on simple prompts like clicks, boxes, or text. Unlike traditional models, it works across many domains without retraining.
2. What is the main difference between SAM 1, SAM 2, and SAM 3?
- SAM 1: Works on static images and requires manual prompts
- SAM 2: Adds video support and real-time object tracking
- SAM 3: Introduces multimodal understanding and more autonomous behavior
👉 In short:
SAM 1 = images → SAM 2 = video → SAM 3 = intelligent perception
3. Is SAM 2 better than SAM 1?
Yes, but it depends on your use case.
- For image segmentation, SAM 1 is still highly effective
- For video and real-time applications, SAM 2 is significantly better
SAM 2 improves:
- Temporal consistency
- Object tracking
- Reduced manual input
4. Is SAM 3 officially released?
As of now, SAM 3 is more of an emerging concept or direction rather than a clearly defined, standalone release. It represents the next phase of SAM evolution, combining:
- Vision
- Language
- Reasoning
5. Can SAM models work in real time?
- SAM 1: ❌ Not real-time
- SAM 2: ✅ Near real-time with optimization
- SAM 3: ✅ Expected to be real-time and more efficient
Real-time performance depends on hardware and implementation.
6. Do SAM models require training on my own dataset?
No, that’s one of their biggest advantages.
SAM models are:
- Pretrained on massive datasets
- Capable of zero-shot segmentation
However, you can fine-tune or adapt them for specialized tasks if needed.
7. What types of prompts can SAM accept?
Depending on the version:
SAM 1 & SAM 2:
- Points (clicks)
- Bounding boxes
- Masks
SAM 3 (emerging):
- Natural language prompts
- Contextual instructions
8. What are the best use cases for SAM 1?
- Image annotation
- Dataset labeling
- Medical imaging segmentation
- Photo editing tools
9. What are the best use cases for SAM 2?
- Video editing
- Object tracking
- Surveillance systems
- Autonomous driving perception
10. What industries benefit the most from SAM models?
SAM models are widely useful across:
- Healthcare (medical imaging)
- Automotive (self-driving systems)
- Media & entertainment (video editing)
- Robotics
- E-commerce (product segmentation)
11. How does SAM compare to traditional segmentation models?
Traditional models like U-Net or Mask R-CNN:
- Require task-specific training
- Need labeled datasets
- Are less flexible
SAM:
- Works across domains
- Requires minimal input
- Generalizes without retraining
12. Can SAM replace all segmentation models?
Not entirely.
While SAM is powerful, traditional models may still be better for:
- Highly specialized tasks
- Low-resource environments
- Scenarios requiring strict optimization
13. Is SAM suitable for mobile or edge devices?
- SAM 1: Heavy for edge deployment
- SAM 2: More optimized but still demanding
- SAM 3: Expected to improve edge performance significantly
14. Does SAM understand objects or just segment shapes?
- SAM 1: Mostly segments shapes
- SAM 2: Adds temporal awareness
- SAM 3: Moves toward semantic understanding
15. What is the future of SAM models?
The future of SAM lies in:
- Multimodal AI (vision + language)
- Autonomous perception systems
- Integration with AI agents and robotics
👉 Ultimately, SAM is evolving from a tool into a core component of intelligent systems.








