


Introduction
In the rapidly evolving world of computer vision, few tasks have garnered as much attention—and driven as much innovation—as object detection and segmentation. From early techniques reliant on hand-crafted features to today’s advanced AI models capable of segmenting anything, the journey has been nothing short of revolutionary. One of the most significant inflection points came with the release of the YOLO (You Only Look Once) family of object detectors, which emphasized real-time performance without significantly compromising accuracy.
Fast forward to 2023, and another major breakthrough emerged: Meta AI’s Segment Anything Model (SAM). SAM represents a shift toward general-purpose models with zero-shot capabilities, capable of understanding and segmenting arbitrary objects—even ones they have never seen before.
This blog explores the fascinating trajectory of object detection and segmentation, tracing its lineage from YOLO to SAM, and uncovering how the field has evolved to meet the growing demands of automation, autonomy, and intelligence.
The Early Days of Object Detection
Before the deep learning renaissance, object detection was a rule-based, computationally expensive process. The classic pipeline involved:
Feature extraction using techniques like SIFT, HOG, or SURF.
Region proposal using sliding windows or selective search.
Classification using traditional machine learning models like SVMs or decision trees.
The lack of end-to-end trainability and high computational cost meant that these methods were often slow and unreliable in real-world conditions.
Viola-Jones Detector
One of the earliest practical solutions for face detection was the Viola-Jones algorithm. It combined integral images and Haar-like features with a cascade of classifiers, demonstrating high speed for its time. However, it was specialized and not generalizable to other object classes.
Deformable Part Models (DPM)
DPMs introduced some flexibility, treating objects as compositions of parts. While they achieved respectable results on benchmarks like PASCAL VOC, their reliance on hand-crafted features and complex optimization hindered scalability.
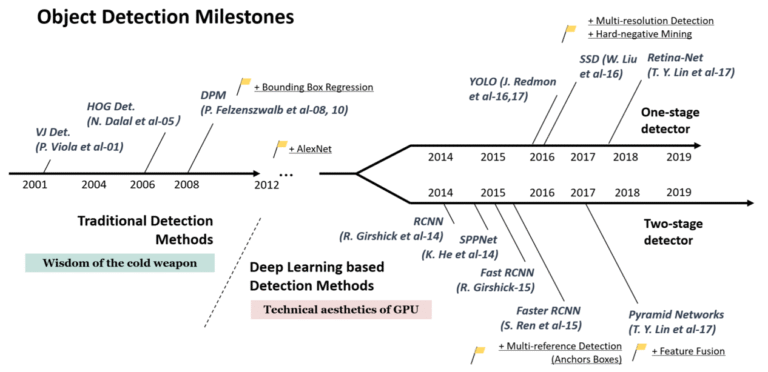
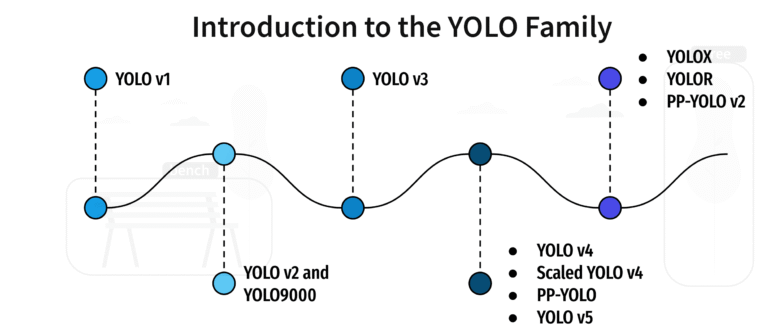
The YOLO Revolution
The launch of YOLO in 2016 by Joseph Redmon marked a significant paradigm shift. YOLO introduced an end-to-end neural network that simultaneously performed classification and bounding box regression in a single forward pass.
YOLOv1 (2016)
Treated detection as a regression problem.
Divided the image into a grid; each grid cell predicted bounding boxes and class probabilities.
Achieved real-time speed (~45 FPS) with decent accuracy.
Drawback: Struggled with small objects and multiple objects close together.
YOLOv2 and YOLOv3 (2017-2018)
Introduced anchor boxes for better localization.
Used Darknet-19 (v2) and Darknet-53 (v3) as backbone networks.
YOLOv3 adopted multi-scale detection, improving accuracy on varied object sizes.
Outperformed earlier detectors like Faster R-CNN in speed and began closing the accuracy gap.
YOLOv4 to YOLOv7: Community-Led Progress
After Redmon stepped back from development, the community stepped up.
YOLOv4 (2020): Introduced CSPDarknet, Mish activation, and Bag-of-Freebies/Bag-of-Specials techniques.
YOLOv5 (2020): Though unofficial, Ultralytics’ YOLOv5 became popular due to its PyTorch base and plug-and-play usability.
YOLOv6 and YOLOv7: Brought further optimizations, custom backbones, and increased mAP across COCO and VOC datasets.
These iterations significantly narrowed the gap between real-time detectors and their slower, more accurate counterparts.
YOLOv8 to YOLOv12: Toward Modern Architectures
YOLOv8 (2023): Focused on modularity, instance segmentation, and usability.
YOLOv9 to YOLOv12 (2024–2025): Integrated transformers, attention modules, and vision-language understanding, bringing YOLO closer to the capabilities of generalist models like SAM.
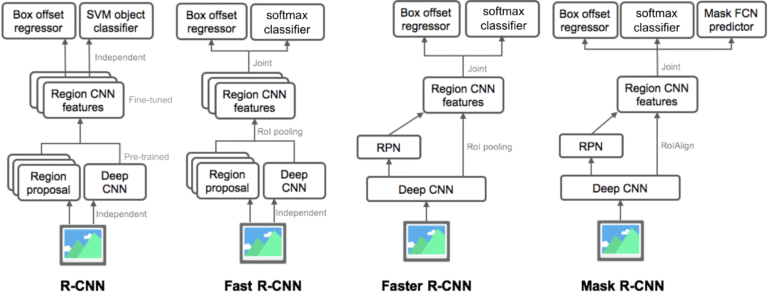
Region-Based CNNs: The R-CNN Family
Before YOLO, the dominant framework was R-CNN, developed by Ross Girshick and team.
R-CNN (2014)
Generated 2000 region proposals using selective search.
Fed each region into a CNN (AlexNet) for feature extraction.
SVMs classified features; regression refined bounding boxes.
Accurate but painfully slow (~47s/image on GPU).
Fast R-CNN (2015)
Improved speed by using a shared CNN for the whole image.
Used ROI Pooling to extract fixed-size features from proposals.
Much faster, but still relied on external region proposal methods.
Faster R-CNN (2016)
Introduced Region Proposal Network (RPN).
Fully end-to-end training.
Became the gold standard for accuracy for several years.
Mask R-CNN
Extended Faster R-CNN by adding a segmentation branch.
Enabled instance segmentation.
Extremely influential, widely adopted in academia and industry.
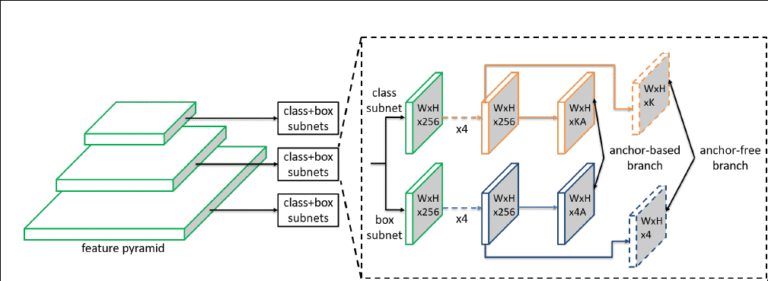
Anchor-Free Detectors: A New Era
Anchor boxes were a crutch that added complexity. Researchers sought anchor-free approaches to simplify training and improve generalization.
CornerNet and CenterNet
Predicted object corners or centers directly.
Reduced computation and improved performance on edge cases.
FCOS (Fully Convolutional One-Stage Object Detection)
Eliminated anchors, proposals, and post-processing.
Treated detection as a per-pixel prediction problem.
Inspired newer methods in autonomous driving and robotics.
These models foreshadowed later advances in dense prediction and inspired more flexible segmentation approaches.
The Rise of Vision Transformers
The NLP revolution brought by transformers was soon mirrored in computer vision.
ViT (Vision Transformer)
Split images into patches, processed them like words in NLP.
Demonstrated scalability with large datasets.
DETR (DEtection TRansformer)
End-to-end object detection using transformers.
No NMS, anchors, or proposals—just direct set prediction.
Slower but more robust and extensible.
DETR variants now serve as a backbone for many segmentation models, including SAM.
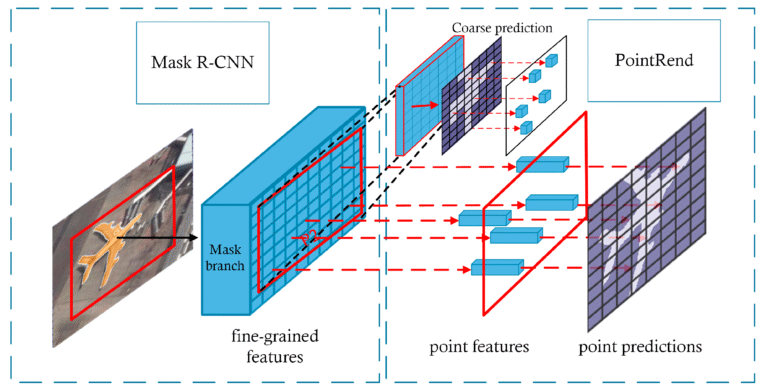
Segmentation in Focus: From Mask R-CNN to DeepLab
Semantic vs. Instance vs. Panoptic Segmentation
Semantic: Classifies every pixel (e.g., DeepLab).
Instance: Distinguishes between multiple instances of the same class (e.g., Mask R-CNN).
Panoptic: Combines both (e.g., Panoptic FPN).
DeepLab Family (v1 to v3+)
Used Atrous (dilated) convolutions for better context.
Excellent semantic segmentation results.
Often combined with backbone CNNs or transformers.
These approaches excelled in structured environments but lacked generality.
Enter SAM: Segment Anything Model by Meta AI
Released in 2023, SAM (Segment Anything Model) by Meta AI broke new ground.
Zero-Shot Generalization
Trained on over 1 billion masks across 11 million images.
Can segment any object with:
Text prompt
Point click
Bounding box
Freeform prompts
Architecture
Based on a ViT backbone.
Features:
Prompt encoder
Image encoder
Mask decoder
Highly parallel and efficient.
Key Strengths
Works out-of-the-box on unseen datasets.
Produces pixel-perfect masks.
Excellent at interactive segmentation.

Comparative Analysis: YOLO vs R-CNN vs SAM
| Feature | YOLO | Faster/Mask R-CNN | SAM |
|---|---|---|---|
| Speed | Real-time | Medium to Slow | Medium |
| Accuracy | High | Very High | Extremely High (pixel-level) |
| Segmentation | Only in recent versions | Strong instance segmentation | General-purpose, zero-shot |
| Usability | Easy | Requires tuning | Plug-and-play |
| Applications | Real-time systems | Research & medical | All-purpose vision |
SAM is not a replacement for YOLO or R-CNN but rather a complementary tool for applications that require flexible and interactive segmentation.
Applications in Industry
Autonomous Vehicles
YOLO: Lane and pedestrian detection.
Mask R-CNN: Object boundary detection.
SAM: Complex environment understanding, rare object segmentation.
Healthcare
Mask R-CNN and DeepLab: Tumor detection, organ segmentation.
SAM: Annotating rare anomalies in radiology scans with minimal data.
Agriculture
YOLO: Detecting pests, weeds, and crops.
SAM: Counting fruits or segmenting plant parts for yield analysis.
Retail & Surveillance
YOLO: Real-time object tracking.
SAM: Tagging items in inventory or crowd segmentation.
Challenges and Limitations
YOLO: Still struggles with extremely small objects.
R-CNNs: Computationally intensive.
SAM:
Heavy on GPU memory.
May over-segment or under-segment in cluttered scenes.
Needs better multimodal understanding.
The Future: Toward Generalist Vision Models
With models like GPT-4V and Gemini showcasing multimodal reasoning, the trend in vision is heading toward foundation models that can:
Understand images, video, and text.
Detect, describe, and reason about content.
Perform segmentation, classification, and generation—all in one.
The fusion of YOLO’s speed, R-CNN’s accuracy, and SAM’s flexibility could form the backbone of next-gen AI.

Conclusion
From YOLO’s real-time breakthroughs to SAM’s generalist capabilities, the evolution of object detection and segmentation reflects the broader trajectory of AI itself: toward faster, smarter, and more generalizable systems. Each milestone has built on the last, bringing us closer to machines that see—and understand—the world as we do.
As we look forward, one thing is clear: the future of computer vision lies not in choosing between YOLO and SAM, but in integrating the strengths of both to build AI systems that are as adaptive, fast, and intelligent as the challenges they’re built to solve.








