


Introduction
The field of computer vision is evolving faster than ever. Traditional object detection models are no longer enough for many modern AI applications. Organizations now require systems capable of identifying previously unseen objects, understanding visual contexts, and performing accurate localization without extensive retraining.
This shift has led to the emergence of innovative models like NVIDIA LocateAnything, which challenges established object detection frameworks such as YOLO (You Only Look Once).
As enterprises build smarter AI systems for robotics, autonomous vehicles, healthcare, retail analytics, and industrial automation, choosing the right vision model becomes increasingly important.
So, how does NVIDIA LocateAnything compare with YOLO? Which model is better for your use case in 2026?
Let’s dive deep into the comparison.
Understanding NVIDIA LocateAnything
NVIDIA LocateAnything is a foundation vision model designed to locate objects within images using natural language prompts.
Unlike traditional object detectors that require predefined categories during training, LocateAnything can identify and localize objects that it has never explicitly seen before.
For example, instead of training a detector specifically for:
- Cars
- Pedestrians
- Traffic signs
A user can simply provide a text prompt such as:
“Locate the red toolbox.”
or
“Find all damaged products.”
The model understands the request and identifies matching objects within the image.
This capability is known as:
- Open-vocabulary object localization
- Language-guided detection
- Prompt-based visual understanding
LocateAnything represents the next generation of vision foundation models that combine computer vision and large language model concepts.

Understanding YOLO
YOLO (You Only Look Once) remains one of the most popular object detection frameworks in the world.
Since its introduction, YOLO has become the industry standard for real-time detection due to its:
- Exceptional speed
- Low latency
- High accuracy
- Easy deployment
Modern versions such as YOLOv11, YOLOv12, and custom enterprise variants continue to dominate applications requiring rapid object detection.
YOLO processes an image in a single forward pass and outputs:
- Bounding boxes
- Class labels
- Confidence scores
The result is highly efficient object detection suitable for edge devices and production environments.

Core Architectural Differences
The biggest difference lies in how each model understands objects.
NVIDIA LocateAnything
LocateAnything relies on foundation-model principles.
It learns broad visual concepts and aligns them with language understanding.
Advantages include:
- Open-vocabulary detection
- Natural language interaction
- Zero-shot localization
- Generalized visual reasoning
The model is not restricted to fixed categories.
YOLO
YOLO follows a supervised object detection approach.
It learns specific object classes during training.
Advantages include:
- High-speed inference
- Lightweight deployment
- Efficient edge processing
- Strong performance on known categories
However, YOLO cannot identify entirely new object classes without retraining.

Detection Flexibility
Detection flexibility is where LocateAnything shines.
Consider a warehouse environment.
A manager wants to locate:
“Damaged cardboard boxes near loading areas.”
YOLO cannot directly perform this task unless:
- Damaged boxes are annotated
- A custom dataset is created
- The model is retrained
LocateAnything can often understand the request immediately through text prompts.
This dramatically reduces dataset preparation costs.
Speed Comparison
When speed matters, YOLO remains difficult to beat.
YOLO Speed Advantages
YOLO is optimized for:
- Real-time video analytics
- Autonomous navigation
- Security surveillance
- Industrial robotics
Modern YOLO models can process dozens or even hundreds of frames per second depending on hardware.
LocateAnything Speed Considerations
LocateAnything prioritizes understanding and flexibility rather than pure speed.
Because it combines visual and semantic reasoning, inference is typically slower.
For applications requiring millisecond-level decisions, YOLO often remains the preferred choice.
Accuracy Comparison
Accuracy depends heavily on the application.
YOLO Accuracy
For predefined object classes:
- Vehicles
- People
- Animals
- Manufacturing defects
YOLO delivers excellent precision and recall.
When trained on high-quality datasets, YOLO can achieve state-of-the-art results.
LocateAnything Accuracy
LocateAnything excels when dealing with:
- Unseen objects
- Complex descriptions
- Semantic queries
- Open-world environments
The model can locate objects that traditional detectors were never trained to recognize.
This creates a significant advantage in dynamic environments.
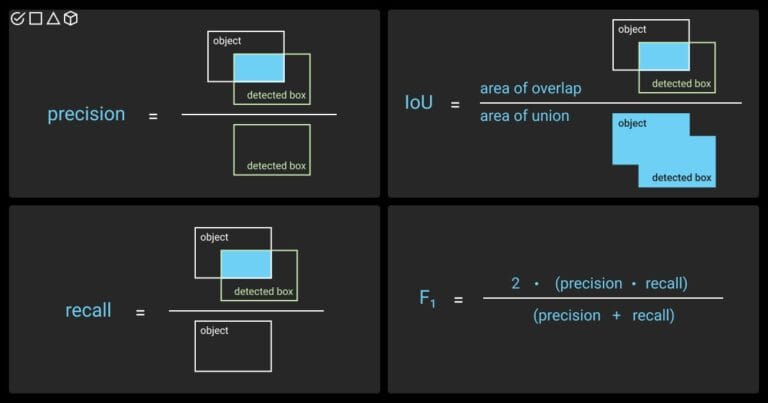
Training Requirements
One of the biggest cost factors in AI deployment is data annotation.
YOLO Requires
- Large annotated datasets
- Bounding box labels
- Class definitions
- Retraining for new categories
Building custom datasets can be expensive and time-consuming.
LocateAnything Requires
- Minimal task-specific training
- Natural language prompts
- Few-shot adaptation
- Zero-shot localization
Organizations can deploy new use cases much faster.
Segmentation and Localization Capabilities
Modern AI systems increasingly require segmentation rather than simple bounding boxes.
LocateAnything integrates naturally with segmentation pipelines.
For example:
- Locate object
- Generate mask
- Perform detailed analysis
This makes it highly compatible with foundation models such as:
- Segment Anything Model (SAM)
- Vision-language models
- Multimodal AI systems
YOLO also supports segmentation variants but generally relies on predefined training classes.
Hardware Requirements
YOLO
Works efficiently on:
- NVIDIA GPUs
- Edge devices
- Jetson platforms
- Embedded systems
- Industrial cameras
Many versions can run in real time on modest hardware.
LocateAnything
Generally requires:
- More GPU memory
- Stronger compute resources
- Foundation-model infrastructure
Organizations should account for higher infrastructure costs.
Real-World Applications
Best Use Cases for YOLO
Autonomous Vehicles
Fast detection of:
- Cars
- Pedestrians
- Road signs
Smart Surveillance
Real-time monitoring and alerts.
Manufacturing
Defect detection on production lines.
Retail Analytics
Customer tracking and inventory monitoring.
Best Use Cases for LocateAnything
Enterprise Search
Locate products using natural language.
Robotics
Understand human instructions.
Industrial Inspection
Find unusual defects without retraining.
Digital Asset Management
Search large image collections semantically.
Medical Imaging
Locate visual patterns described through text.
NVIDIA LocateAnything vs YOLO: Feature Comparison
| Feature | NVIDIA LocateAnything | YOLO |
|---|---|---|
| Open-Vocabulary Detection | Yes | No |
| Real-Time Performance | Moderate | Excellent |
| Zero-Shot Learning | Yes | Limited |
| Custom Training Required | Minimal | Extensive |
| Edge Deployment | Limited | Excellent |
| Language Understanding | Yes | No |
| New Object Discovery | Excellent | Poor |
| Production Maturity | Emerging | Very High |
| Segmentation Integration | Strong | Good |
| Resource Efficiency | Moderate | Excellent |
Which Model Should You Choose?
The answer depends entirely on your project requirements.
Choose YOLO if you need:
- Real-time detection
- Edge deployment
- Low latency
- Known object categories
- Cost-efficient inference
Choose LocateAnything if you need:
- Open-world detection
- Natural language search
- Zero-shot localization
- Flexible AI workflows
- Foundation-model capabilities
Many organizations will ultimately combine both approaches.
A common architecture in 2026 is:
- YOLO performs rapid object detection.
- LocateAnything handles semantic searches.
- SAM generates precise segmentation masks.
- LLMs interpret results and automate decisions.
This hybrid approach delivers both speed and intelligence.
The Future of Object Detection
The future is moving toward foundation vision models capable of understanding images much like humans do.
Traditional detectors such as YOLO will continue dominating:
- Edge AI
- Robotics
- Industrial automation
Meanwhile, models like LocateAnything represent the next evolution of visual intelligence, enabling AI systems to reason about images using natural language.
Rather than replacing YOLO, LocateAnything expands what computer vision systems can accomplish.
The most advanced AI pipelines in 2026 increasingly combine both technologies to create highly accurate, scalable, and adaptable vision systems.

Conclusion
The comparison between NVIDIA LocateAnything and YOLO is not simply a battle between two object detection models. It represents two different philosophies of computer vision.
YOLO remains the king of real-time object detection, delivering unmatched speed, efficiency, and deployment flexibility.
NVIDIA LocateAnything introduces a new paradigm, enabling AI systems to locate objects through language, understand unseen categories, and operate in open-world environments.
For enterprises building next-generation AI solutions, the best choice often depends on whether speed or flexibility is the primary requirement.
As AI vision systems continue evolving, organizations that successfully combine both approaches will be best positioned to unlock the full potential of computer vision.
Frequently Asked Questions (FAQ)
What is NVIDIA LocateAnything?
NVIDIA LocateAnything is an open-vocabulary object localization model that identifies objects using natural language prompts rather than fixed categories.
Is NVIDIA LocateAnything better than YOLO?
It depends on the use case. LocateAnything is better for open-world and language-guided detection, while YOLO is better for real-time object detection.
Can LocateAnything detect objects without training?
Yes. It supports zero-shot localization, allowing it to find objects based on text prompts without task-specific training.
Why is YOLO still popular in 2026?
YOLO offers exceptional speed, low latency, strong accuracy, and efficient deployment on edge devices.
Can LocateAnything and YOLO work together?
Yes. Many modern AI pipelines use YOLO for rapid detection and LocateAnything for semantic understanding and open-vocabulary search.
Which model is better for robotics?
For real-time navigation, YOLO is often preferred. For instruction-based robotic systems that understand natural language, LocateAnything offers significant advantages.
Is LocateAnything suitable for industrial inspection?
Yes. It can identify unusual defects and object categories without requiring extensive retraining, making it useful for dynamic industrial environments.
What is the future of object detection?
The future lies in combining fast detectors like YOLO with foundation models such as LocateAnything and segmentation models like SAM to create intelligent multimodal vision systems.








