Introduction
Object detection has undergone a remarkable transformation over the past decade. What began with handcrafted features and classical computer vision techniques has evolved into sophisticated deep learning systems capable of understanding complex visual environments. Models like YOLO, Faster R-CNN, and SSD pushed the boundaries of speed and accuracy, enabling real-world applications such as autonomous driving, smart surveillance, and industrial automation.
However, as applications became more complex, the limitations of traditional convolutional neural networks (CNNs) became more apparent—particularly their difficulty in capturing long-range dependencies and global context within images. This challenge led to the rise of transformer-based architectures, which revolutionized natural language processing and soon made their way into computer vision.
While transformers introduced a powerful way to model global relationships in images, early implementations like DETR struggled with slow inference speeds, making them impractical for real-time applications. This created a clear gap in the field: models were either fast or highly accurate—but rarely both.
RT-DETR (Real-Time Detection Transformer) emerges as a solution to this problem. It represents a new generation of object detection models that successfully combines the global reasoning capabilities of transformers with the efficiency required for real-time performance. By rethinking the architecture and optimizing key components, RT-DETR makes transformer-based detection viable for real-world, time-sensitive applications.
In this blog, we explore how RT-DETR works, what makes it unique, and why it is quickly becoming a cornerstone in modern computer vision systems
What is RT-DETR?
RT-DETR is a vision transformer-based object detection model designed for real-time applications. It builds on the DETR (Detection Transformer) framework but introduces optimizations that significantly improve inference speed.
Unlike traditional detectors:
- It is end-to-end (no pipeline fragmentation)
- It eliminates Non-Maximum Suppression (NMS)
- It directly predicts final object detections
RT-DETR was introduced in the paper:
“DETRs Beat YOLOs on Real-time Object Detection” (2023)
Why RT-DETR Matters
RT-DETR bridges a long-standing gap in computer vision:
- Transformers → excellent global reasoning, but slow
- CNN detectors (like YOLO) → fast, but less contextual
RT-DETR merges both worlds through a hybrid architecture, enabling:
- Real-time inference
- Strong accuracy
- Simplified deployment
Key Features of RT-DETR
1. Real-Time Performance
RT-DETR achieves real-time speeds while maintaining high detection accuracy.
2. End-to-End Detection (No NMS)
No anchor boxes and no NMS means a simpler and faster pipeline.
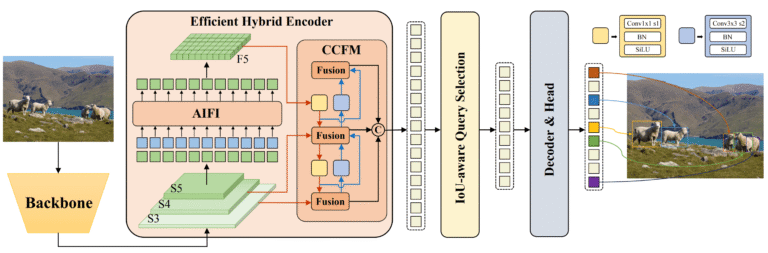
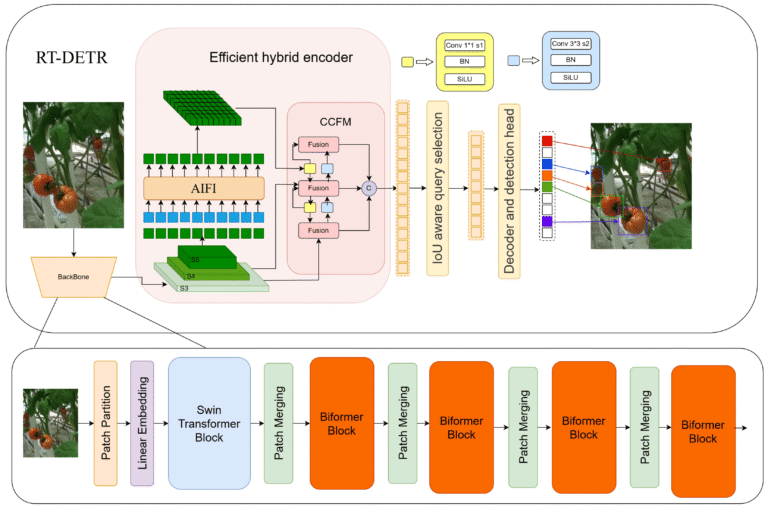
3. Hybrid Encoder Design
Combines CNN backbones with transformer attention mechanisms.
4. Efficient Attention (AIFI)
Optimized attention reduces computational cost.
5. Query Selection Optimization
Processes only the most relevant object queries.
6. Flexible Model Variants
Includes scalable versions like RT-DETR-L and RT-DETR-X.
How RT-DETR Works
- Feature extraction via CNN
- Hybrid encoding (CNN + Transformer)
- Object queries interact with features
- Predictions (class + bounding boxes)
- Direct output without NMS
RT-DETR vs Other Object Detectors
| Model | Speed | Accuracy | Pipeline Complexity |
|---|---|---|---|
| YOLO | Very Fast | High | Moderate |
| Faster R-CNN | Slow | Very High | High |
| DETR | Slow | Very High | High |
| RT-DETR | Fast | Very High | Low |
Advantages of RT-DETR
- Real-time transformer-based detection
- End-to-end architecture
- No NMS or anchor boxes
- Strong global context understanding
- Scalable and flexible
Limitations
- Requires GPU for best performance
- Transformer components can be memory-intensive
- Still evolving compared to mature CNN models
Use Cases
- Autonomous vehicles
- Surveillance systems
- Retail analytics
- Robotics
- Smart cities
Citations and Acknowledgments
Official Citation (BibTeX)
@misc{lv2023detrs,
title={DETRs Beat YOLOs on Real-time Object Detection},
author={Wenyu Lv and Shangliang Xu and Yian Zhao and Guanzhong Wang and Jinman Wei and Cheng Cui and Yuning Du and Qingqing Dang and Yi Liu},
year={2023},
eprint={2304.08069},
archivePrefix={arXiv},
primaryClass={cs.CV}
}Acknowledgments
RT-DETR was developed by Baidu and supported by the PaddlePaddle team, helping advance real-time transformer-based detection and making it accessible through frameworks like Ultralytics.
Future of RT-DETR
- Edge-optimized lightweight models
- Better small-object detection
- Improved training efficiency
- Integration with multimodal AI systems
Conclusion
RT-DETR marks a significant milestone in the evolution of object detection. It demonstrates that the long-standing trade-off between speed and accuracy is no longer inevitable. By intelligently combining CNN-based feature extraction with transformer-based global reasoning, RT-DETR delivers a powerful, efficient, and streamlined detection framework.
What truly sets RT-DETR apart is its end-to-end design philosophy. By eliminating the need for anchor boxes and post-processing steps like Non-Maximum Suppression, it simplifies the detection pipeline while maintaining high performance. This not only reduces computational overhead but also makes the model easier to deploy and scale across different environments.
As industries increasingly rely on real-time visual intelligence—from autonomous vehicles navigating busy streets to smart cities analyzing live video feeds—the demand for models like RT-DETR will continue to grow. Its ability to process complex scenes quickly and accurately makes it a strong candidate for next-generation AI systems.
Looking ahead, we can expect further advancements in transformer efficiency, edge deployment capabilities, and integration with multimodal AI systems. RT-DETR is not just an incremental improvement—it represents a shift toward more intelligent, efficient, and practical object detection models.
For developers, researchers, and businesses alike, adopting RT-DETR means staying ahead in a rapidly evolving AI landscape. It’s more than just a model—it’s a glimpse into the future of computer vision, where speed, simplicity, and intelligence converge seamlessly.
FAQ (Frequently Asked Questions)
1. What does RT-DETR stand for?
RT-DETR stands for Real-Time Detection Transformer, a fast and accurate object detection model based on transformer architecture.
2. How is RT-DETR different from YOLO?
RT-DETR uses transformers for global context and does not require NMS, while YOLO is CNN-based and relies on post-processing. RT-DETR aims to match YOLO’s speed with better contextual understanding.
3. Does RT-DETR require NMS?
No. RT-DETR is an end-to-end model that eliminates the need for Non-Maximum Suppression.
4. Is RT-DETR suitable for real-time applications?
Yes. RT-DETR is specifically designed for real-time inference, making it ideal for video analytics, robotics, and autonomous systems.
5. Who developed RT-DETR?
RT-DETR was developed by Baidu with contributions from the PaddlePaddle research team.
6. What are RT-DETR model variants?
Common variants include:
- RT-DETR-L (Large)
- RT-DETR-X (Extra Large)
These provide different trade-offs between speed and accuracy.
7. Is RT-DETR better than DETR?
Yes, in terms of speed. RT-DETR significantly improves inference time while maintaining similar accuracy.