


Introduction
Edge AI integrates artificial intelligence (AI) capabilities directly into edge devices, allowing data to be processed locally. This minimizes latency, reduces network traffic, and enhances privacy. YOLO (You Only Look Once), a cutting-edge real-time object detection model, enables devices to identify objects instantaneously, making it ideal for edge scenarios. Optimizing YOLO for Edge AI enhances real-time applications, crucial for systems where latency can severely impact performance, like autonomous vehicles, drones, smart surveillance, and IoT applications. This blog thoroughly examines methods to effectively optimize YOLO, ensuring efficient operation even on resource-constrained edge devices.
Understanding YOLO and Edge AI
YOLO operates by dividing an image into grids, predicting bounding boxes, and classifying detected objects simultaneously. This single-pass method dramatically boosts speed compared to traditional two-stage detection methods like R-CNN. However, running YOLO on edge devices presents challenges, such as limited computing resources, energy efficiency demands, and hardware constraints. Edge AI mitigates these issues by decentralizing data processing, yet it introduces constraints like limited memory, power, and processing capabilities, requiring specialized optimization methods to efficiently deploy robust AI models like YOLO. Successfully deploying YOLO at the edge involves balancing accuracy, speed, power consumption, and cost.

YOLO Versions and Their Impact
Different YOLO versions significantly impact performance characteristics on edge devices. YOLO v3 emphasizes balance and robustness, utilizing multi-scale predictions to enhance detection accuracy. YOLO v4 improves on these by integrating advanced training methods like Mish activation and Cross Stage Partial connections, enhancing accuracy without drastically affecting inference speed. YOLO v5 further optimizes deployment by reducing the model’s size and increasing inference speed, ideal for lightweight deployments on smaller hardware. YOLO v8 represents the latest advances, incorporating modern deep learning innovations for superior performance and efficiency.
| YOLO Version | FPS (Jetson Nano) | mAP (mean Average Precision) | Size (MB) |
|---|---|---|---|
| YOLO v3 | 25 | 33.0% | 236 |
| YOLO v4 | 28 | 43.5% | 244 |
| YOLO v5 | 32 | 46.5% | 27 |
| YOLO v8 | 35 | 49.0% | 24 |
Selecting the appropriate YOLO version depends heavily on the application’s specific needs, balancing factors such as required accuracy, speed, memory footprint, and device capabilities.

Hardware Considerations for Edge AI
Hardware selection directly affects YOLO’s performance at the edge. Central Processing Units (CPUs) provide versatility and general compatibility but typically offer moderate inference speeds. Graphics Processing Units (GPUs), optimized for parallel computation, deliver higher speeds but consume significant power and require cooling solutions. Tensor Processing Units (TPUs), specialized for neural networks, provide even faster inference speeds with comparatively better power efficiency, yet their specialized nature often comes with higher costs and compatibility considerations. Neural Processing Units (NPUs), specifically designed for AI workloads, achieve optimal performance in terms of speed, efficiency, and energy consumption, often preferred for mobile and IoT applications.
| Hardware Type | Inference Speed | Power Consumption | Cost |
|---|---|---|---|
| CPU | Moderate | Low | Low |
| GPU | High | High | Medium |
| TPU | Very High | Medium | High |
| NPU | Highest | Low | High |
Detailed benchmarking is essential when selecting hardware, taking into consideration not only raw performance metrics but also factors such as power budgets, thermal constraints, ease of integration, software compatibility, and total cost of ownership.

Model Optimization Techniques
Optimizing YOLO for edge deployment involves methods such as pruning, quantization, and knowledge distillation. Model pruning involves systematically reducing model complexity by removing unnecessary connections and layers without significantly affecting accuracy. Quantization reduces computational precision from floating-point (FP32) to lower bit-depth representations such as INT8, drastically reducing memory footprint and computational load, significantly boosting inference speed.
Code Example (Quantization in PyTorch):
import torch
from torch.quantization import quantize_dynamic
model_fp32 = torch.load('yolo.pth')
model_int8 = quantize_dynamic(model_fp32, {torch.nn.Linear}, dtype=torch.qint8)
torch.save(model_int8, 'yolo_quantized.pth')
Knowledge distillation involves training smaller, more efficient models (students) to replicate performance from larger models (teachers), preserving accuracy while significantly reducing computational overhead.
Deployment Strategies for Edge
Effective deployment involves leveraging technologies like Docker, TensorFlow Lite, and PyTorch Mobile, which simplify managing environments and model distribution across diverse edge devices. Docker containers standardize deployment environments, facilitating seamless updates and scalability. TensorFlow Lite provides a lightweight runtime optimized for edge devices, offering efficient execution of quantized models.
Code Example (TensorFlow Lite):
import tensorflow as tf
converter = tf.lite.TFLiteConverter.from_saved_model('yolo_model')
tflite_model = converter.convert()
with open('yolo_edge.tflite', 'wb') as f:
f.write(tflite_model)
PyTorch Mobile similarly facilitates model deployment on mobile and edge devices, simplifying model serialization, reducing runtime overhead, and enabling efficient execution directly on-device without needing extensive computational resources.
Advanced Techniques for Real-Time Performance
Real-time performance requires advanced strategies like frame skipping, batching, and hardware acceleration. Frame skipping involves selectively processing frames based on relevance, significantly reducing computational load. Batching aggregates multiple data points for parallel inference, efficiently leveraging hardware capabilities.
Code Example (Batch Inference):
batch_size = 4
for i in range(0, len(images), batch_size):
batch = images[i:i+batch_size]
predictions = model(batch)
Hardware acceleration uses specialized processors or instructions sets like CUDA for GPUs or dedicated NPU hardware instructions, maximizing computational throughput and minimizing latency.
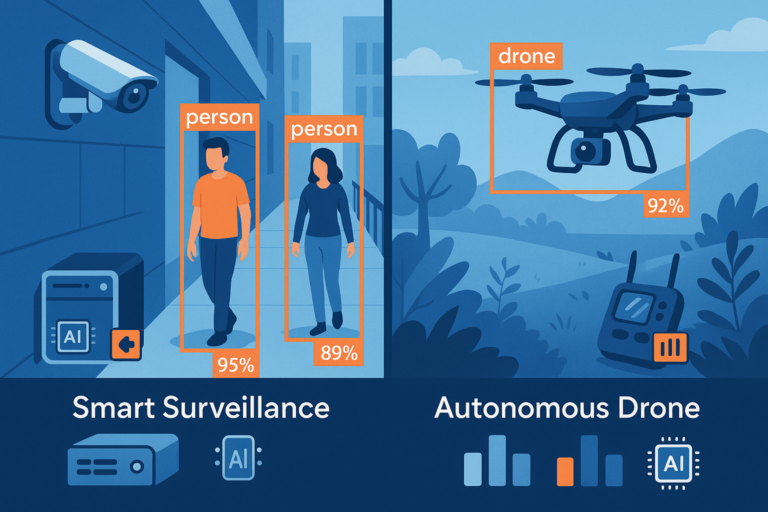
Case Studies
Real-world applications highlight practical implementations of optimized YOLO. Smart surveillance systems utilize YOLO for real-time object detection to enhance security, identify threats instantly, and reduce response time. Autonomous drones deploy optimized YOLO for navigation, obstacle avoidance, and real-time decision-making, crucial for operational safety and effectiveness.
Smart Surveillance System Example
Each application underscores specific optimizations, hardware considerations, and deployment strategies, demonstrating the significant benefits achievable through careful optimization.
Future Trends
Emerging trends in Edge AI and YOLO include the integration of neuromorphic chips, federated learning, and novel deep learning techniques aimed at further reducing latency and enhancing inference capabilities. Neuromorphic chips simulate neural processes for highly efficient computing. Federated learning allows decentralized model training directly on edge devices, enhancing data privacy and efficiency. Future iterations of YOLO are expected to leverage these technologies to push boundaries further in real-time object detection performance.

Conclusion
Optimizing YOLO for Edge AI entails comprehensive approaches encompassing model selection, hardware optimization, deployment strategies, and advanced techniques. The continuous evolution in both hardware and software landscapes promises even more powerful, efficient, and practical edge AI applications.








