



Pose estimation is a vital task in computer vision that involves detecting the positions and orientations of key points on a human or object. Applications span a wide range of fields, including sports analysis, healthcare, and animation.
YOLO (You Only Look Once) models have revolutionized object detection with their speed and accuracy. With YOLOv11, pose estimation capabilities are seamlessly integrated, offering a unified solution for detecting objects and their poses.
This comprehensive guide explores how to use YOLOv11 for pose estimation. Whether you’re developing a fitness tracking app or analyzing biomechanics, this guide equips you with the tools and knowledge to leverage YOLOv11 effectively.
Understanding Pose Estimation
What is Pose Estimation?
Pose estimation predicts the spatial coordinates of key points in an object or person, such as joints in a human body or key features in machinery. These coordinates form a “skeleton” representing the pose.
Key Elements:
- Keypoints: Specific points like elbows, knees, or object edges.
- Skeleton: A connection of keypoints to form a meaningful structure.
Applications of Pose Estimation:
- Sports Analytics: Tracking athletes’ movements to improve performance.
- Healthcare: Monitoring patients’ postures for rehabilitation.
- Gaming and AR/VR: Powering motion tracking for immersive experiences.
- Robotics: Assisting robots in understanding human actions.
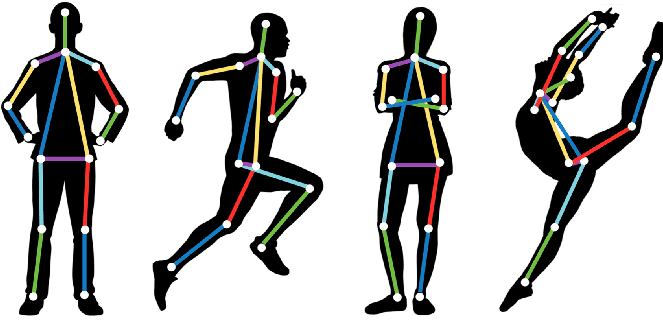
YOLOv11 and Pose Estimation
YOLOv11 enhances pose estimation with advanced architecture, combining the efficiency of YOLO with the precision of keypoint detection.
Key Features of YOLOv11 for Pose Estimation:
- Transformer-Based Backbone: Improved feature extraction for better keypoint localization.
- Anchor-Free Detection: Enhances keypoint prediction for objects of varying scales.
- Multi-Task Learning: Supports simultaneous object detection and pose estimation.
Comparison with Other Pose Estimation Models:
| Feature | YOLOv11 | OpenPose | HRNet |
|---|---|---|---|
| Speed | Real-time | Slower | Moderate |
| Accuracy | High | Very High | Very High |
| Scalability | Excellent | Limited | Moderate |
| Deployment | Optimized for edge | Requires high-end GPUs | Requires high-end GPUs |
Setting Up YOLOv11 for Pose Estimation
System Requirements:
To use YOLOv11 for pose estimation, ensure your system meets the following specifications:
- Hardware:
- GPU with at least 8GB VRAM (NVIDIA recommended).
- 16GB RAM or higher.
- SSD for faster data access.
- Software:
- Python 3.8+.
- PyTorch or TensorFlow.
- CUDA and cuDNN for GPU acceleration.
Installation Process:
Clone the YOLOv11 repository:
git clone https://github.com/your-repo/yolov11.git
cd yolov112. Install Dependencies:
Create a virtual environment and install the required packages:
pip install -r requirements.txt
3. Verify Installation:
Run a test script to ensure YOLOv11 is installed correctly:
python test_installation.pyDownloading Pretrained Models and Datasets
Download YOLOv11 models trained for pose estimation:
wget https://path-to-weights/yolov11-pose.pt

Understanding YOLOv11 Configuration for Pose Estimation
Configuring YOLOv11 for Keypoint Detection:
The configuration file (yolov11-pose.yaml) includes details about:
- Keypoints: The number of keypoints to detect.
- Connections: Define how keypoints are linked to form skeletons.
- Architecture: Specify layers for keypoint prediction.
Dataset Preparation for Pose Estimation:
Prepare data in COCO format:
- Annotations: Include keypoint coordinates and visibility flags.
- Folder Structure:
data/
train/
val/
annotations/
train.json
val.jsonHyperparameter Adjustments:
Fine-tune parameters in the configuration file:
- Learning Rate (
lr0): Initial learning rate for training. - Batch Size (
batch_size): Adjust based on GPU memory. - Epochs (
epochs): Number of training iterations.
Training YOLOv11 for Pose Estimation
Fine-Tuning on Custom Datasets:
Adapt YOLOv11 to your dataset by running:
python train.py --cfg yolov11-pose.yaml --data pose_dataset.yaml --weights yolov11-pose.pt --epochs 100
Transfer Learning for Pose Estimation:
Use pretrained weights to speed up training:
python train.py --weights yolov11-pretrained.pt --data pose_dataset.yaml --freeze-layers
Monitoring Training and Performance:
- mAP: Mean Average Precision for pose estimation.
- Loss Curves: Monitor classification, bounding box, and keypoint losses.

Running Inference with YOLOv11
Pose Estimation on Single Images:
python detect.py --weights yolov11-pose.pt --img path/to/image.jpg --task pose
Batch Processing and Video Inference:
Process an entire dataset or video file:
python detect.py --weights yolov11-pose.pt --source path/to/video.mp4 --task pose
Real-Time Pose Estimation:
Use a webcam for real-time inference:
python detect.py --weights yolov11-pose.pt --source 0 --task pose
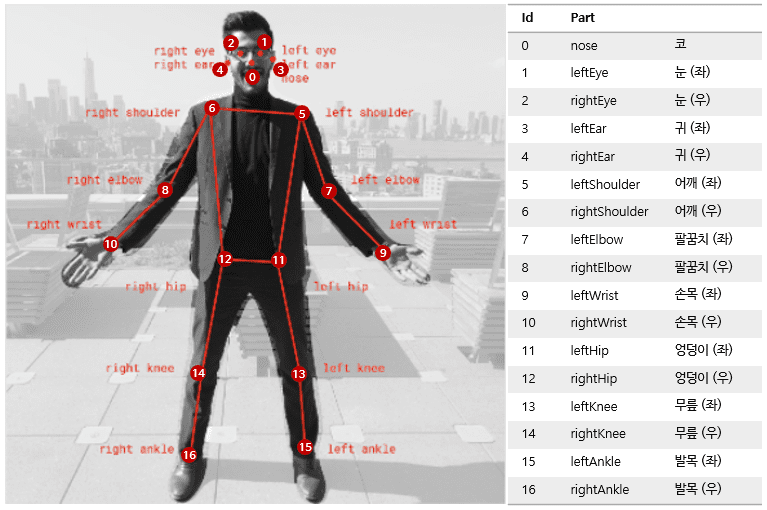
Optimizing YOLOv11 for Pose Estimation
Optimization plays a critical role in enhancing YOLOv11’s performance for pose estimation. Whether your goal is to achieve higher accuracy, faster inference, or seamless deployment on edge devices, these techniques can make a significant difference.
Improving Accuracy
Data Augmentation
- Augment your dataset to increase diversity and reduce overfitting:
- Random Rotation: Adds robustness to rotations by mimicking real-world variations.
- Scaling: Allows the model to detect keypoints in objects of varying sizes.
- Cropping and Padding: Simulates occlusions and incomplete views.
- Example using Albumentations for augmentation:
- Augment your dataset to increase diversity and reduce overfitting:
import albumentations as A
transform = A.Compose([
A.Rotate(limit=20, p=0.5),
A.HorizontalFlip(p=0.5),
A.RandomBrightnessContrast(p=0.2),
A.Resize(640, 640)
])
2. Hyperparameter Tuning
- Adjust parameters to fine-tune performance:
- Learning Rate: Start with
lr0=0.01and decay gradually. - Batch Size: Use smaller batches if GPU memory is limited but increase epochs.
- Epochs: Train for longer durations if overfitting is not an issue.
- Learning Rate: Start with
- Use tools like Optuna for automated hyperparameter optimization:
import optuna
def objective(trial):
lr = trial.suggest_loguniform('lr', 1e-5, 1e-1)
batch_size = trial.suggest_int('batch_size', 16, 64)
# Implement the training logic with the selected parameters
3. Pretraining and Transfer Learning
- Start with YOLOv11 pretrained on large datasets like COCO.
- Fine-tune with domain-specific datasets to enhance accuracy in niche applications.
4. Loss Function Improvements
- Modify loss functions to emphasize keypoint precision:
- Combine Mean Squared Error (MSE) for keypoints with Cross-Entropy Loss for classification.
- Modify loss functions to emphasize keypoint precision:
Reducing Computational Overhead
Pruning
- Remove redundant weights and layers to reduce model size without significantly impacting accuracy:
from torch.nn.utils import prune
prune.l1_unstructured(model.layer, name='weight', amount=0.2)
2. Quantization
- Convert model weights from FP32 to INT8 or FP16 to accelerate inference:
quantized_model = torch.quantization.quantize_dynamic(
model, {torch.nn.Linear}, dtype=torch.qint8
)
3. Dynamic Resolution Scaling
- Use adaptive resolution scaling to reduce computation for smaller objects while maintaining accuracy.
4. Model Compression
- Compress the model using techniques like knowledge distillation, transferring knowledge from a large model to a smaller one.
Deployment on Edge Devices
Model Conversion
- Export the YOLOv11 model to ONNX or TensorRT for deployment:
python export.py --weights yolov11-pose.pt --img 640 --batch-size 1
2. Device Optimization
- Deploy on devices like NVIDIA Jetson Nano, Coral TPU, or Raspberry Pi:
- Use TensorRT for NVIDIA devices.
- Use Edge TPU compiler for Coral devices.
- Deploy on devices like NVIDIA Jetson Nano, Coral TPU, or Raspberry Pi:
3. Power Efficiency
- Enable hardware acceleration for low-power consumption:
- NVIDIA Jetson offers nvpmodel to optimize power usage.
- Enable hardware acceleration for low-power consumption:
4. Streamlined Inference
- Implement real-time pose estimation using lightweight frameworks like Flask or FastAPI for API-based applications.
Case Studies and Real-World Applications
Case Study 1: Sports Analytics
A professional soccer league implemented YOLOv11 for tracking players’ movements and postures during matches.
Implementation:
- Fine-tuned YOLOv11 on a custom dataset of soccer players.
- Augmented data with variations in lighting and crowd density.
- Integrated pose estimation results into a dashboard for coaches.
Results:
- Enhanced strategy analysis by identifying player fatigue and efficiency.
- Achieved real-time processing at 30 FPS, even in high-action sequences.
Challenges and Solutions:
- Challenge: Occlusion during crowded scenes.
- Solution: Multi-view camera setups to reconstruct poses.
Case Study 2: Healthcare and Rehabilitation
A physiotherapy center used YOLOv11 for monitoring patients’ movements during rehabilitation exercises.
Implementation:
- Annotated keypoints for different exercises (e.g., bending, squatting).
- Deployed the model on an NVIDIA Jetson Nano for edge inference.
- Provided visual feedback to patients in real time.
Results:
- Reduced patient injuries by ensuring correct posture.
- Improved recovery rates by analyzing compliance with prescribed movements.
Challenges and Solutions:
- Challenge: Variability in patient body types and movement speed.
- Solution: Augmented training data to include diverse body shapes and slow-motion videos.
Case Study 3: Augmented Reality Gaming
A gaming company integrated YOLOv11 for real-time pose estimation in an AR-based fitness game.
Implementation:
- Used YOLOv11 to detect keypoints for arms, legs, and torso.
- Integrated pose estimation with Unity 3D for real-time feedback.
Results:
- Achieved immersive gameplay with low-latency pose tracking.
- Increased user engagement by providing real-time rewards for correct movements.
Challenges and Solutions:
- Challenge: Low-light environments.
- Solution: Trained the model with augmented low-light images.

Future of Pose Estimation and YOLOv11
Emerging Trends in Pose Estimation
Self-Supervised Learning
- Reduce reliance on labeled data by using self-supervised techniques for learning human poses.
Transformer-Based Architectures
- YOLOv11’s hybrid use of transformers shows the future direction of pose estimation models, with improved spatial and temporal understanding.
Multi-Modal Integration
- Combine pose estimation with other modalities like depth data, audio, or text for richer context.
Edge AI Advancements
- The push for edge AI will result in even more efficient models capable of high-performance pose estimation on resource-constrained devices.
Synthetic Data Generation
- Leverage AI-generated synthetic datasets to train models for rare or difficult-to-capture poses.
The Role of YOLOv11 in Future Developments
Real-Time Applications
- YOLOv11’s unmatched speed positions it as the go-to choice for applications requiring real-time inference, such as live sports analysis or surveillance.
Integration with AR/VR
- YOLOv11 will play a pivotal role in improving AR/VR experiences, enabling lifelike interactions through precise pose estimation.
Scalability Across Industries
- From robotics to healthcare, YOLOv11’s flexible architecture ensures its relevance across diverse domains.
Improved Generalization
- Future iterations of YOLO may further improve generalization, making models less dependent on large labeled datasets.
Conclusion
YOLOv11 has revolutionized pose estimation by combining speed, accuracy, and scalability. From sports analytics to healthcare and gaming, its versatility makes it a valuable tool across industries. With further optimizations and innovations on the horizon, YOLOv11 is poised to remain at the forefront of pose estimation technology.
Dive into YOLOv11, experiment with its capabilities, and unlock the potential of real-time pose estimation in your projects. The possibilities are limitless—let YOLOv11 transform the way you approach pose estimation. Happy coding!








