


Introduction
Object detection is a cornerstone of computer vision. From autonomous vehicles navigating bustling city streets to medical systems identifying cancerous lesions in radiographs, the importance of accurate and efficient object detection has never been greater.
Among the most influential object detection models, YOLO, Faster R-CNN, and SSD have consistently topped the benchmarks. Now, with the introduction of YOLOv12, the landscape is evolving rapidly, pushing the boundaries of speed and accuracy further than ever before.
This guide offers a deep, critical comparison between YOLOv12, Faster R-CNN, and SSD—highlighting the strengths, limitations, and unique use cases of each.
What is Object Detection?
At its core, object detection involves two tasks:
- Classification: Identifying what the object is.
- Localization: Determining where it is via bounding boxes.
Unlike image classification, object detection can detect multiple objects of different classes in a single image. Object detectors are generally grouped into two categories:
- One-stage detectors: YOLO, SSD
- Two-stage detectors: Faster R-CNN, R-FCN
One-stage detectors prioritize speed, while two-stage detectors typically offer better accuracy but slower inference times.

Overview of the Models
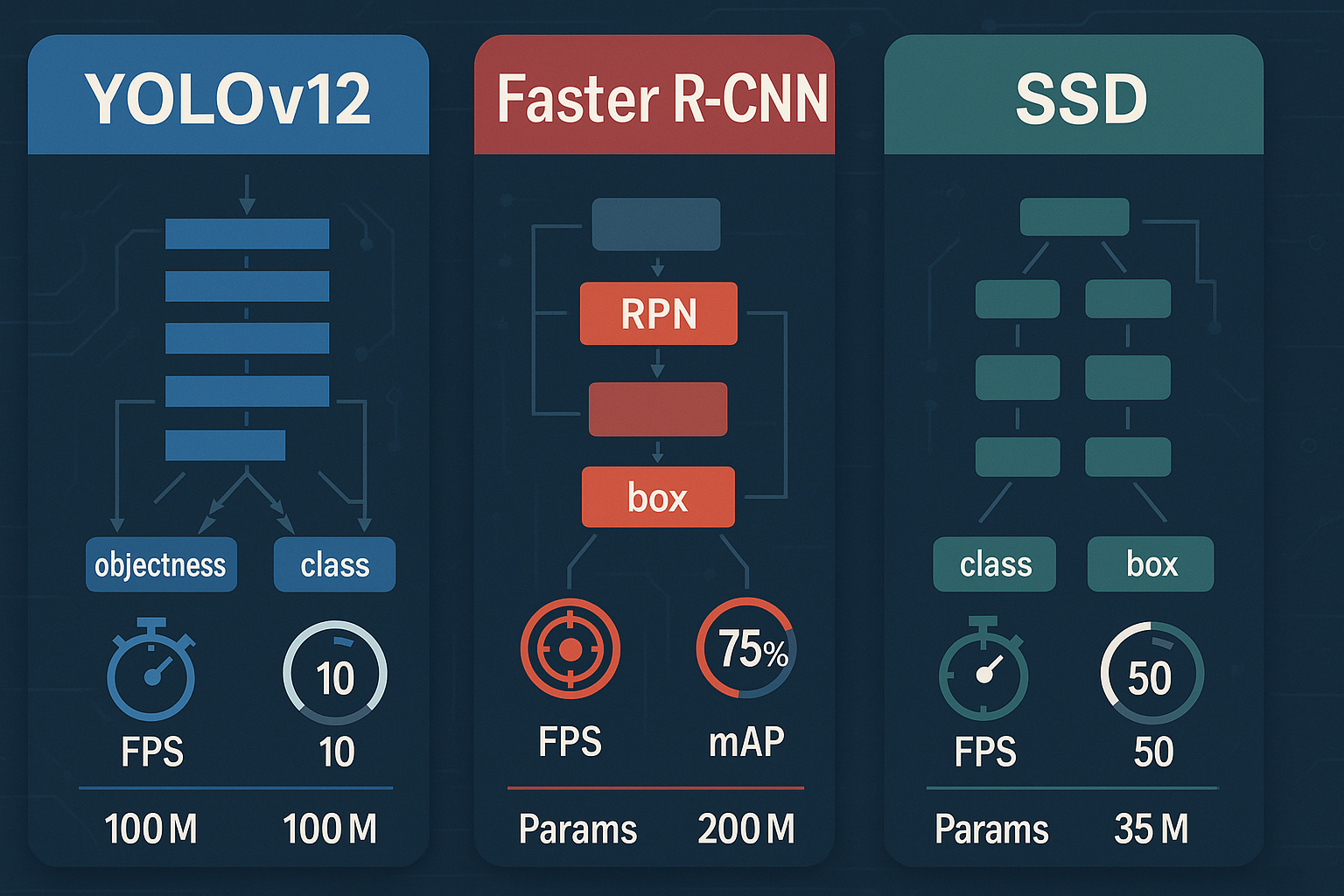
YOLOv12
The YOLO series (You Only Look Once) revolutionized real-time object detection. YOLOv12, introduced in 2025, combines:
- Efficient backbone (e.g., CSPNeXt)
- Transformer-enhanced neck (RT-DETR inspired)
- High-resolution detection
- Multi-head classification
- Integrated instance segmentation
Faster R-CNN
Introduced in 2015 by Ren et al., Faster R-CNN uses a Region Proposal Network (RPN) to speed up detection while maintaining accuracy. Used in:
- Medical imaging
- Satellite imagery
- Surveillance
SSD (Single Shot MultiBox Detector)
SSD offers a middle-ground between YOLO and Faster R-CNN. Key variants include:
- SSD300 / SSD512
- MobileNet-SSD
Model Architectures
YOLOv12
- Backbone: CSPNeXt / EdgeViT
- Neck: PANet + Transformer encoder
- Head: Decoupled detection heads
- Innovations: Multi-task learning, dynamic anchor-free heads, cross-scale attention
Faster R-CNN
- RPN + ROI Head
- Backbone: ResNet / Swin
- ROI Pooling + Classification head
SSD
- Base: VGG16 / MobileNet
- Extra convolution layers + multibox head
Feature Extraction and Backbones
| Model | Backbone Options | Notable Traits |
|---|---|---|
| YOLOv12 | CSPNeXt, EfficientNet, ViT | High-speed, modular, transformer-compatible |
| Faster R-CNN | ResNet, Swin, ConvNeXt | High capacity, excellent generalization |
| SSD | VGG16, MobileNet, Inception | Lightweight, less expressive for small objects |
Detection Heads and Output Mechanisms
| Feature | YOLOv12 | Faster R-CNN | SSD |
|---|---|---|---|
| Number of heads | 3+ (box, class, mask) | RPN + Classifier | Per feature map |
| Anchor type | Anchor-free | Anchor-based | Anchor-based |
| Output refinement | IoU + DFL + NMS | Softmax + Smooth L1 | Sigmoid + smooth loss |
Performance Metrics
Benchmark Comparison
| Model | mAP@0.5:0.95 | FPS (V100) | Params (M) | Best Feature |
|---|---|---|---|---|
| YOLOv12 | 55–65% | 75–180 | 50–120 | Real-time + segmentation |
| Faster R-CNN | 42–60% | 7–15 | 130–250 | High precision |
| SSD | 30–45% | 25–60 | 35–60 | Speed & accuracy |
⚙️ Memory Footprint
- YOLOv12: 500MB–2GB
- Faster R-CNN: 4GB+
- SSD: ~1–2GB
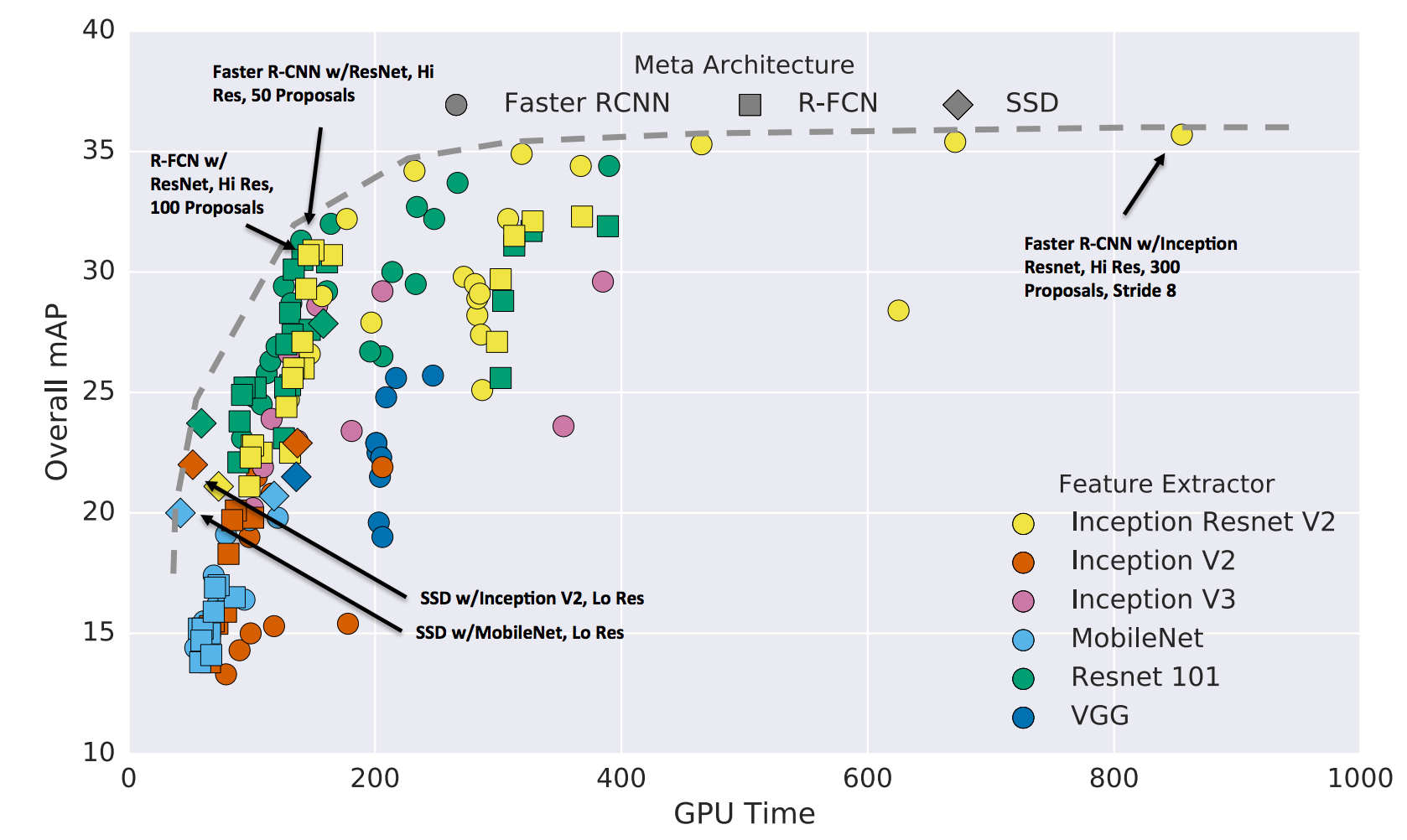
Training Requirements and Dataset Sensitivity
| Feature | YOLOv12 | Faster R-CNN | SSD |
|---|---|---|---|
| Training Speed | Fast | Slow | Moderate |
| Hardware Needs | 1 GPU (8–16GB) | 2+ GPUs (24GB+) | 1 GPU |
| Small Object Bias | Good | Excellent | Poor–Moderate |
| Augmentation | Mosaic, MixUp | Limited | Flip, Scale |
Real-World Use Cases and Industry Applications
| Industry | Model | Application |
|---|---|---|
| Autonomous Cars | YOLOv12 | Pedestrian, sign, vehicle detection |
| Retail | SSD | Shelf monitoring |
| Healthcare | Faster R-CNN | Tumor detection |
| Drones | YOLOv12 | Target tracking |
| Robotics | SSD | Grasp planning |
| Smart Cities | Faster R-CNN | Crowd monitoring |

Pros and Cons Comparison
YOLOv12
- Pros: Real-time, segmentation built-in, edge deployable
- Cons: Slightly lower accuracy on complex datasets
Faster R-CNN
- Pros: Best accuracy, dense scene handling
- Cons: Slow, heavy for edge deployment
SSD
- Pros: Lightweight, fast
- Cons: Weak for small objects, outdated features
Future Trends and Innovations
- Unified vision models (YOLO-World, Grounded SAM)
- Transformer-powered detectors (RT-DETR)
- Edge optimization (TensorRT, ONNX)
- Cross-modal detection (text, image, video)
Conclusion
| Use Case | Best Model |
|---|---|
| High-speed detection | YOLOv12 |
| Medical or satellite | Faster R-CNN |
| Embedded/IoT | SSD |
| Segmentation | YOLOv12 |
Each model has its place. Choose based on your project’s accuracy, speed, and deployment needs.
References and Further Reading
- Redmon et al. (2016). You Only Look Once
- Ren et al. (2015). Faster R-CNN
- Liu et al. (2016). SSD
- Ultralytics YOLOv5 GitHub
- OpenMMLab YOLOv8/YOLOv9
- TensorFlow Object Detection API







