
Introduction: The Shift to AI-Powered Scraping
In the early days of the internet, scraping websites was a relatively straightforward process: write a script, pull HTML content, and extract the data you need. But as websites have grown more complex—powered by JavaScript, dynamically rendered content, and anti-bot defenses—traditional scraping tools have begun to show their limits.
That’s where AI-powered web scraping enters the picture.
AI fundamentally changes the game. It brings adaptability, contextual understanding, and even human-like reasoning into the automation process. Rather than just pulling raw HTML, AI models can:
Understand the meaning of content (e.g., detect job titles, product prices, reviews)
Automatically adjust to structural changes on a site
Recognize visual elements using computer vision
Act as intelligent agents that decide what to extract and how
This guide explores how you can use modern AI tools to build autonomous data bots—systems that not only scrape data but also adapt, scale, and reason like a human.
What Is Web Scraping?
Web scraping is the automated extraction of data from websites. It’s used to:
Collect pricing and product data from e-commerce stores
Monitor job listings or real estate sites
Aggregate content from blogs, news, or forums
Build datasets for machine learning or analytics
🔧 Typical Web Scraping Workflow
Send HTTP request to retrieve a webpage
Parse the HTML using a parser (like
BeautifulSouporlxml)Select specific elements using CSS selectors, XPath, or Regex
Store the output in a structured format (e.g., CSV, JSON, database)
Example (Traditional Python Scraper):
import requests
from bs4 import BeautifulSoup
url = "https://example.com/products"
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
for item in soup.select(".product"):
name = item.select_one(".title").text
price = item.select_one(".price").text
print(name, price)
This approach works well on simple, static sites—but struggles on modern web apps.
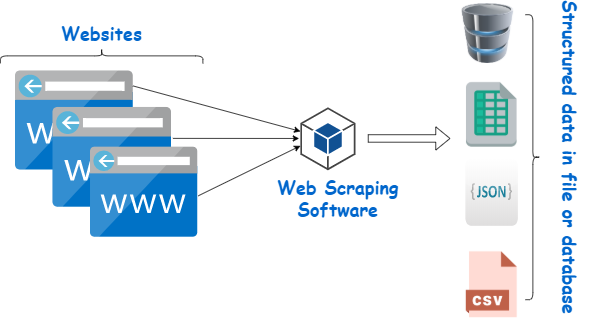
The Limitations of Traditional Web Scraping
Traditional scraping relies on the fixed structure of a page. If the layout changes, your scraper breaks. Other challenges include:
❌ Fragility of Selectors
CSS selectors and XPath can stop working if the site structure changes—even slightly.
❌ JavaScript Rendering
Many modern websites load data dynamically with JavaScript. requests and BeautifulSoup don’t handle this. You’d need headless browsers like Selenium or Playwright.
❌ Anti-Bot Measures
Sites may detect and block bots using:
CAPTCHA challenges
Rate limiting / IP blacklisting
JavaScript fingerprinting
❌ No Semantic Understanding
Traditional scrapers extract strings, not meaning. For example:
It might extract all text inside
<div>, but can’t tell which one is the product name vs. price.It cannot infer that a certain block is a review section unless explicitly coded.
Why AI?
To overcome these challenges, we need scraping tools that can:
Understand content contextually using Natural Language Processing (NLP)
Adapt dynamically to site changes
Simulate human interaction using Reinforcement Learning or agents
Work across multiple modalities (text, images, layout)
How AI is Transforming Web Scraping
Traditional web scraping is rule-based — it depends on fixed logic like soup.select(".title"). In contrast, AI-powered scraping is intelligent, capable of adjusting dynamically to changes and understanding content meaningfully.
Here’s how AI is revolutionizing web scraping:
1. Visual Parsing & Layout Understanding
AI models can visually interpret the page — like a human reading it — using:
Computer Vision to identify headings, buttons, and layout zones
Image-based OCR (e.g., Tesseract, PaddleOCR) to read embedded text
Semantic grouping of elements by role (e.g., identifying product blocks or metadata cards)
Example: Even if a price is embedded in a styled image banner, AI can extract it using visual cues.
2. Semantic Content Understanding
LLMs (like GPT-4) can:
Understand what a block of text is (title vs. review vs. disclaimer)
Extract structured fields (name, price, location) from unstructured text
Handle multiple languages, idiomatic expressions, and abbreviations
“Extract all product reviews that mention battery life positively” is now possible using AI, not regex.
3. Self-Healing Scrapers
With traditional scraping, a single layout change breaks your scraper. AI agents can:
Detect changes in structure
Infer the new patterns
Relearn or regenerate selectors using visual and semantic clues
Tools like Diffbot or AutoScraper demonstrate this resilience.
4. Human Simulation and Reinforcement Learning
Using Reinforcement Learning (RL) or RPA (Robotic Process Automation) principles, AI scrapers can:
Navigate sites by clicking buttons, filling search forms
Scroll intelligently based on viewport content
Wait for dynamic content to load (adaptive delays)
AI agents powered by LLMs + Playwright can mimic a human user journey.
5. Language-Guided Agents (LLMs)
Modern scrapers can now be directed by natural language. You can tell an AI:
“Find all job listings for Python developers in Berlin under $80k”
And it will:
Parse your intent
Navigate the correct filters
Extract results contextually
Key Technologies Behind AI-Driven Scraping
To build intelligent scrapers, here’s the modern tech stack:
| Technology | Use Case |
|---|---|
| LLMs (GPT-4, Claude, Gemini) | Interpret HTML, extract fields, generate selectors |
| Playwright / Puppeteer | Automate browser-based actions (scrolling, clicking, login) |
| OCR Tools (Tesseract, PaddleOCR) | Read embedded or scanned text |
| spaCy / Hugging Face Transformers | Extract structured text (names, locations, topics) |
| LangChain / Autogen | Chain LLM tools for agent-like scraping behavior |
| Vision-Language Models (GPT-4V, Gemini Vision) | Multimodal understanding of webpages |
Agent-Based Frameworks (Next-Level)
AutoGPT + Playwright: Autonomous agents that determine what and how to scrape
LangChain Agents: Modular LLM agents for browsing and extraction
Browser-native AI Assistants: Future trend of GPT-integrated browsers

Tools and Frameworks to Get Started
To build an autonomous scraper, you’ll need more than just HTML parsers. Below is a breakdown of modern scraping components, categorized by function.
⚙️ A. Core Automation Stack
| Tool | Purpose | Example |
|---|---|---|
Playwright | Headless browser automation (JS sites) | page.goto("https://...") |
Selenium | Older alternative to Playwright | Slower but still used |
Requests | Simple HTTP requests (static pages) | requests.get(url) |
BeautifulSoup | HTML parsing with CSS selectors | soup.select("div.title") |
lxml | Faster XML/HTML parsing | Good for large files |
Tesseract | OCR for images | Extracts text from PNGs, banners |
🧠 B. AI & Language Intelligence
| Tool | Role |
|---|---|
OpenAI GPT-4 | Understands, extracts, and transforms HTML data |
Claude, Gemini, Groq LLMs | Alternative or parallel agents |
LangChain | Manages chains of LLM tasks (e.g., page load → extract → verify) |
LlamaIndex | Indexes HTML/text for multi-step reasoning |
📊 C. NLP and Post-Processing
| Tool | Purpose |
|---|---|
spaCy | Named Entity Recognition (e.g., extract names, dates) |
transformers | Contextual analysis of long documents |
pandas | Clean, organize, and export data |
☁️ D. Cloud / UI Automation
| Tool | Purpose |
|---|---|
Apify | Actor-based cloud scraping & scheduling |
Browse AI | No-code, point-and-click scraping bots |
Octoparse | Visual scraper with scheduling features |
Zapier + AI | Automate when scraping triggers happen |
System Architecture of AI Scraper (Conceptual)
[User Instruction] → [Prompt Generator]
↓
┌────────────────────┐
[Webpage] → → → │ LLM (e.g., GPT-4) │
└────────────────────┘
↓
[Extracted JSON] ← [HTML + Page DOM]
[OCR Layer] ← [Screenshot] ← [Browser Page]
This flow shows how user intent, the DOM structure, and AI reasoning combine to produce structured data.
Setting Up Your First AI-Powered Scraper
Let’s now walk through how to build a basic autonomous scraper from scratch.
1. Install Requirements (Jupyter/Colab Compatible)
!pip install playwright openai beautifulsoup4
!playwright install
For OCR support:
!apt install tesseract-ocr
!pip install pytesseract
2. Load Web Page with Playwright
from playwright.sync_api import sync_playwright
def load_page_html(url):
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto(url, timeout=60000)
html = page.content()
browser.close()
return html
3. Send HTML to GPT-4 for Semantic Extraction
import openai
def extract_with_gpt(html, instruction):
prompt = f"""
You are an expert HTML parser. Based on the instruction below, extract structured data in JSON format.
Instruction: {instruction}
HTML:
{html[:6000]} # Truncated for token limit
"""
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}]
)
return response['choices'][0]['message']['content']
4. Full Example Pipeline
url = "https://example.com/news"
html = load_page_html(url)
instruction = "Extract all article titles and their publication dates."
results = extract_with_gpt(html, instruction)
print(results)

Advanced Prompt Engineering for LLM Extraction
LLMs need precise prompts to extract high-quality data. Example enhancements:
🧾 Example Prompt 1: Product Listings
You are a smart data agent. From the provided HTML, extract a list of products in the following JSON format:
[
{"title": "...", "price": "...", "rating": "..."}
]
Only include the top 10 visible results. Ignore hidden elements.
🧾 Example Prompt 2: Table Extraction
From the HTML below, extract the content of all tables into CSV format. Include column headers. Ignore footers or advertisements.
Saving and Structuring the Results
Save as JSON:
with open("output.json", "w", encoding="utf-8") as f:
f.write(results)
Save as CSV:
import pandas as pd
import json
data = json.loads(results)
df = pd.DataFrame(data)
df.to_csv("results.csv", index=False)
Handling Common Errors
| Error | Solution |
|---|---|
Too many tokens | Truncate or split the HTML |
NavigationTimeoutError | Increase timeout in Playwright |
JSONDecodeError | Add try/except or use regex to fix malformed JSON |
| Empty output | Improve prompt clarity or specify HTML section |
Best Practices
Throttle requests: Add
page.wait_for_timeout(2000)to mimic human behavior.Use selectors + LLM: Pre-filter the content you send to the model.
Chain tasks: Use LangChain or your own scripts to:
Load → Parse → Verify → Store
Validate outputs: Check extracted JSON with schema validation (e.g.,
pydantic)Cache outputs: Use hashing + local cache to avoid redundant API calls
Optional: Add OCR for Visual Content
from PIL import Image
import pytesseract
def extract_text_from_image(image_path):
img = Image.open(image_path)
text = pytesseract.image_to_string(img)
return text
Use this on screenshots from Playwright:
page.screenshot(path="screenshot.png")
ocr_text = extract_text_from_image("screenshot.png")
Ethical and Legal Considerations
As AI-based scraping becomes more powerful, the responsibility to use it ethically and legally increases. Below are the key dimensions to consider:
⚖️ A. Legality and Terms of Use
Respect
robots.txt:This file tells crawlers which parts of a site can or cannot be accessed.
Violating it may not be illegal in all jurisdictions, but it often violates terms of service.
Follow Website Terms of Service:
Many websites explicitly prohibit automated data collection.
You risk IP bans, cease-and-desist letters, or legal action if you ignore ToS.
Do Not Circumvent Authentication:
Avoid scraping content hidden behind logins or paywalls without permission.
Automated login to bypass access control can be illegal under laws like the CFAA (US).
🔐 B. Privacy, Consent, and Data Protection
Avoid Personal Data Without Consent:
This includes names, emails, phone numbers, and social profiles.
GDPR, CCPA, and other laws impose strict penalties for collecting personal information without explicit consent.
Focus on Public, Aggregated Data:
Collecting reviews, product specs, or article headlines is usually safe.
Avoid scraping identifiable user comments, profiles, or photos.
Log Your Activities Transparently:
Keep a log of what you scraped, when, and for what purpose.
Helps demonstrate ethical intent and assists with debugging.
🚦 C. Load Management and Site Impact
Throttle Your Requests:
Scrapers should not hit servers with hundreds of requests per second.
Use
time.sleep()orPlaywright.wait_for_timeout()between actions.
Use Rotating Proxies Respectfully:
Rotating IPs to bypass bans can be ethical if used to maintain fairness, not to evade rules.
Respect Pagination and Rate Limits:
Fetch data gradually, simulate human scrolls or navigation.
🧾 D. Copyright and Content Ownership
Just Because It’s Public Doesn’t Mean It’s Free:
Many websites own the content they display.
Republishing scraped content without permission can violate copyright laws.
When in Doubt, Attribute or Link Back:
Always credit the source if you’re republishing text, images, or full articles.
Use Data for Internal Insights, Not Direct Monetization:
It’s generally safer to analyze than to redistribute.
Use Cases Where Autonomous Scraping Excels
Autonomous AI-powered scraping outperforms traditional tools in domains that involve:
High structural variability
Dynamic rendering
Semantic complexity
Let’s break down some top real-world applications:
🏬 E-Commerce Intelligence
| Use Case | Benefit |
|---|---|
| Competitor Price Tracking | Adjust pricing dynamically |
| Product Availability | Alert users when items restock |
| Feature Extraction | Build comparison datasets |
| User Sentiment Mining | Extract product reviews for NLP analysis |
Use Case: Monitor product prices and availability from a JavaScript-heavy online store.
from playwright.sync_api import sync_playwright
import openai
url = "https://example.com/search?q=laptop"
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto(url)
html = page.content()
browser.close()
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[{
"role": "user",
"content": f"Extract the product names, prices, and availability from this HTML:\n{html[:6000]}"
}]
)
print(response['choices'][0]['message']['content'])
🏠 Real Estate Monitoring
| Use Case | Benefit |
|---|---|
| Property Listings | Track inventory, pricing, features |
| Location Metadata | Extract geolocation, size, amenities |
| Investment Scouting | Analyze deal opportunities across sites |
url = "https://example.com/properties?city=Berlin"
html = load_page_html(url)
instruction = """
Extract real estate listings. Output as JSON with:
- property_title
- price
- address
- square_footage
- number_of_bedrooms
"""
response = extract_with_gpt(html, instruction)
print(response)
🧪 Clinical Research and Healthcare
| Use Case | Benefit |
|---|---|
| Scraping Clinical Trial Databases | Build datasets for drug research |
| Extracting from Open Access Journals | Feed LLMs with latest medical findings |
| Disease Trend Analysis | Monitor public health data for insights |
url = "https://clinicaltrials.gov/ct2/results?cond=cancer&recrs=b"
html = load_page_html(url)
instruction = """
Extract trial data as a list of JSON objects with:
- trial_title
- recruiting_status
- location
- study_type
- phase
"""
response = extract_with_gpt(html, instruction)
print(response)
📰 News, Forums, and Media
| Use Case | Benefit |
|---|---|
| Headline Aggregation | Build custom news dashboards |
| Sentiment & Topic Classification | Track media narratives across regions |
| Forum Data Mining | Fuel training data for chatbots or NLP models |
url = "https://example-news.com/latest"
html = load_page_html(url)
instruction = "Extract a list of article headlines and their publication dates from this HTML."
response = extract_with_gpt(html, instruction)
print(response)
🧠 LLM Dataset Building
| Use Case | Benefit |
|---|---|
| Collecting Q&A Pairs | Supervised fine-tuning for domain-specific tasks |
| Instruction-Tuning Prompts | Build instruction-response pairs for SFT |
| Story/Dialogue Extraction | Power conversational agents in specific genres |
url = "https://example.com/help-center"
html = load_page_html(url)
instruction = """
Extract Q&A pairs suitable for training a chatbot. Format:
[
{"question": "...", "answer": "..."},
...
]
"""
response = extract_with_gpt(html, instruction)
print(response)
Tips for Success with All Use Cases
| Strategy | Why It Matters |
|---|---|
| Truncate long HTML | LLMs have token limits |
| Clean HTML first | Remove ads, navigation bars |
| Add structural hints | Use page.locator() to pre-filter |
| Validate JSON | Check output structure before saving |
| Log & rate-limit | Ethical and functional best practice |
The Future of Web Scraping: AI + Autonomy
Web scraping is undergoing a major transformation — from rule-based scripts to intelligent, agent-driven data explorers. Here’s what’s emerging:
A. LLM-Driven Autonomous Agents
Example: Agents like AutoGPT, CrewAI, or LangGraph can:
Navigate to a website
Determine what to extract
Decide how to store or act on the data
Re-run automatically as websites update
Use case: “Build me a dataset of iPhone prices from Amazon, Newegg, and Walmart weekly.”
Instead of writing three scrapers, a single autonomous agent does the task with AI reasoning + web control.
B. Natural Language Interfaces for Scraping
You’re no longer tied to writing code or XPath selectors.
Example:
“Get all laptops under $1000 with 16GB RAM from BestBuy and save it to CSV.”
An LLM could:
Interpret the task
Launch a headless browser
Extract relevant listings
Save structured output
Tools emerging in this space:
LangChain + Playwright agents
GPT-4 + Puppeteer integrations
Voice-controlled scraping (experimental)
C. Synthetic Dataset Generation
In AI training workflows, scraping is no longer just about gathering data — it’s also about creating training-ready formats.
You can now:
Crawl articles → summarize them with GPT → build multi-language datasets
Extract Q&A pairs → automatically generate distractors for MCQs
Scrape discussions → use LLMs to simulate dialogue variations
Combine scraping + generation to build:
Chatbot training corpora
Instruction-following examples
Domain-specific prompts and completions
D. Smart Scheduling & Re-crawling with LLMs
Instead of running cron jobs blindly, AI can:
Monitor a website’s update frequency
Trigger scraping only when new content is detected
Prioritize pages based on semantic change (not just URL change)
Example:
If the price has changed by >5%, or a product goes out of stock → trigger re-scrape.
Combining AI Tools into a Full Autonomous Scraping Stack
| Layer | Tools |
|---|---|
| Navigation & Control | Playwright, Puppeteer, Selenium |
| Content Understanding | GPT-4, Claude, Gemini, Groq |
| Chaining & Agents | LangChain, CrewAI, Autogen |
| Storage | Pandas, SQLite, Pinecone, Weaviate |
| Orchestration | Airflow, Prefect, Apify, Zapier |
| Monitoring | Logs, alerts, anomaly detection via LLM |
Google Colab Deployment Template
This template runs scraping with Playwright and OpenAI GPT-4 in Google Colab.
Colab Notebook Outline: AI Scraper with OpenAI
# Install required packages
!pip install playwright openai beautifulsoup4
!playwright install
# Imports
from playwright.sync_api import sync_playwright
import openai
# Load Page HTML
def load_page_html(url):
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto(url, timeout=60000)
html = page.content()
browser.close()
return html
# Send HTML to GPT-4
def extract_with_gpt(html, instruction):
prompt = f"""
You are an intelligent HTML parser. Follow this instruction:
Instruction: {instruction}
HTML:
{html[:6000]}
"""
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}]
)
return response['choices'][0]['message']['content']
# Run Example
url = "https://example.com/products"
html = load_page_html(url)
instruction = "Extract product titles and prices as a JSON array."
output = extract_with_gpt(html, instruction)
print(output)
AWS Lambda Deployment Template
Run scraping + GPT on AWS Lambda via a container image with Playwright installed.
lambda_function.py
import json
import openai
from playwright.sync_api import sync_playwright
def load_page_html(url):
with sync_playwright() as p:
browser = p.chromium.launch()
page = browser.new_page()
page.goto(url, timeout=60000)
html = page.content()
browser.close()
return html
def lambda_handler(event, context):
url = event.get("url", "")
instruction = event.get("instruction", "")
if not url or not instruction:
return {"statusCode": 400, "body": json.dumps({"error": "Missing URL or instruction"})}
html = load_page_html(url)
prompt = f"Instruction: {instruction}\nHTML:\n{html[:6000]}"
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}]
)
return {
"statusCode": 200,
"body": json.dumps({"result": response['choices'][0]['message']['content']})
}
Dockerfile (for Lambda container image)
FROM public.ecr.aws/lambda/python:3.9
# Install system dependencies for Playwright
RUN yum install -y wget unzip && \
pip install --upgrade pip
# Install Python dependencies
COPY requirements.txt .
RUN pip install -r requirements.txt
# Install Playwright + Browsers
RUN pip install playwright && playwright install
# Copy your code
COPY lambda_function.py .
# Lambda entry point
CMD ["lambda_function.lambda_handler"]
requirements.txt
playwright
openai
Final Recommendations for Builders
| Advice | Why |
|---|---|
| ✅ Use AI to supplement, not fully replace logic | LLMs are powerful but need guardrails |
| ✅ Prototype with simple prompts | Complexity grows fast — keep instructions concise |
| ✅ Stay ethical and transparent | Future regulations will tighten on AI scraping |
| ✅ Start small, scale smart | Begin with one website and modular code |
| ✅ Log and audit everything | Helps with debugging and compliance |
Final Thoughts
AI is revolutionizing scraping not just as a tool, but as an intelligent partner in data collection. You’re no longer just pulling HTML — you’re building systems that:
Understand
Adapt
Decide
Act autonomously
The days of writing brittle scrapers for every single website are fading. In their place are AI-powered agents that speak your language, work across domains, and scale with minimal supervision.
The future of scraping is not code — it’s intent.








