


Object detection is a cornerstone of computer vision, enabling machines to identify and locate objects within images and videos. It powers applications ranging from autonomous vehicles and surveillance systems to retail analytics and medical imaging. Over the years, numerous algorithms and models have been developed, but none have made as significant an impact as the YOLO (You Only Look Once) family of models.
The YOLO series is renowned for its speed and accuracy, offering real-time object detection capabilities that have set benchmarks in the field. YOLOv11, the latest iteration, builds on its predecessors with groundbreaking advancements in architecture, precision, and efficiency. It introduces innovative features that address prior limitations and push the boundaries of what’s possible in object detection.
This series is a comprehensive guide to using YOLOv11 for object detection. Whether you’re a beginner looking to understand the basics or an experienced practitioner aiming to master its advanced functionalities, this tutorial covers everything you need to know. By the end, you’ll be equipped to set up, train, and deploy YOLOv11 for various use cases, from simple projects to large-scale deployments.
Understanding YOLOv11
Evolution of YOLO Models
The journey of YOLO began with YOLOv1, introduced in 2016 by Joseph Redmon. Its key innovation was treating object detection as a regression problem, predicting bounding boxes and class probabilities directly from images in a single pass. Over time, subsequent versions—YOLOv2, YOLOv3, and so forth—improved accuracy, expanded support for multiple scales, and enhanced feature extraction capabilities.
YOLOv11 represents the pinnacle of this evolution. It integrates advanced techniques such as transformer-based backbones, enhanced feature pyramid networks, and improved anchor-free mechanisms. These enhancements make YOLOv11 not only faster but also more robust in handling complex datasets and diverse environments.
Key Advancements in YOLOv11
- Improved Backbone Architecture: YOLOv11 employs a hybrid backbone combining convolutional and transformer layers, providing superior feature representation.
- Dynamic Head Design: The detection head adapts dynamically to different object scales, enhancing accuracy for small and overlapping objects.
- Better Anchoring: Anchor-free detection reduces the need for manual tuning, streamlining training and inference.
- Optimization for Edge Devices: YOLOv11 is optimized for deployment on resource-constrained devices, enabling efficient edge computing.
Applications of YOLOv11
- Autonomous Driving: Real-time detection of pedestrians, vehicles, and traffic signals.
- Healthcare: Identifying anomalies in medical images.
- Retail Analytics: Monitoring customer behavior and inventory tracking.
- Surveillance: Enhancing security through object detection in video feeds.
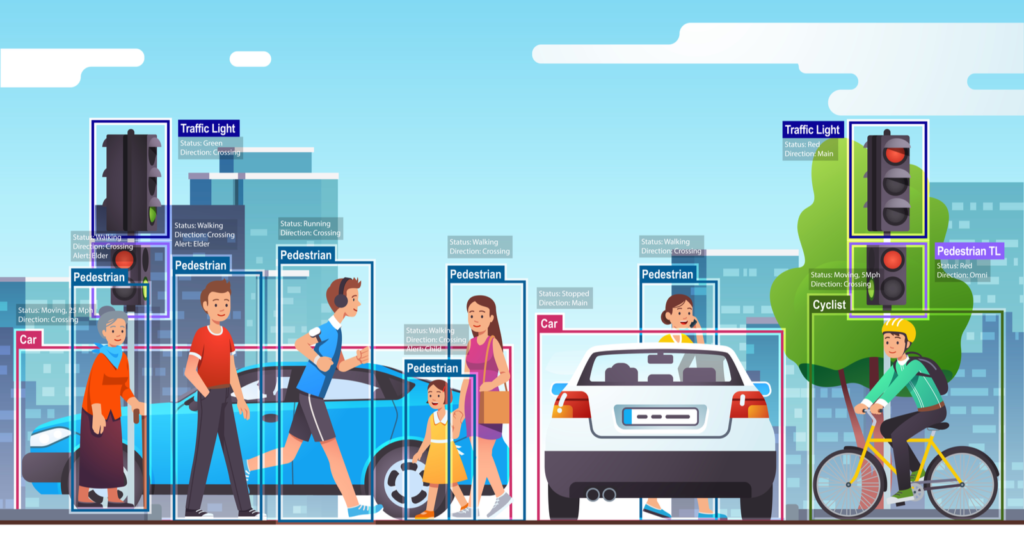
Setting Up YOLOv11
System Requirements
To achieve optimal performance with YOLOv11, ensure your system meets the following requirements:
Hardware:
- GPU with at least 8GB VRAM (NVIDIA recommended).
- CPU with multiple cores for preprocessing tasks.
- Minimum 16GB RAM.
Software:
- Python 3.8 or higher.
- CUDA Toolkit and cuDNN for GPU acceleration.
- PyTorch or TensorFlow (depending on the implementation).
Installation Process
Clone the Repository:
git clone https://github.com/your-repo/yolov11.git
cd yolov112. Install Dependencies:
Create a virtual environment and install the required packages:
pip install -r requirements.txt
3. Verify Installation:
Run a test script to ensure YOLOv11 is installed correctly:
python test_installation.pyPrerequisites and Dependencies
Familiarity with Python programming, basic machine learning concepts, and experience with tools like PyTorch or TensorFlow will help you get the most out of this guide.

Getting Started with YOLOv11
Downloading Pretrained Models
Pretrained YOLOv11 models are available for download from official repositories or community contributors. Choose the model variant (e.g., small, medium, large) based on your use case and computational resources.
wget https://path-to-yolov11-model/yolov11-large.ptUnderstanding YOLOv11 Configuration Files
Configuration files dictate the model’s architecture, dataset paths, and training parameters. Key sections include:
- Model Architecture: Defines the layers and connections.
- Dataset Paths: Specifies locations of training and validation datasets.
- Hyperparameters: Sets learning rates, batch sizes, and optimizer settings.
Dataset Preparation
YOLOv11 supports formats like COCO and Pascal VOC. Annotate your images using tools like LabelImg or Roboflow, and ensure the annotations are saved in the correct format.
Training YOLOv11
Configuring Hyperparameters
Customize the following parameters in the configuration file:
- Batch Size: Adjust based on GPU memory.
- Learning Rate: Use a scheduler for dynamic adjustment.
- Epochs: Set based on dataset size and complexity.
Training on Custom Datasets
Run the training script with your dataset:
python train.py --cfg yolov11.yaml --data my_dataset.yaml --epochs 50
Using Transfer Learning
Leverage pretrained weights to fine-tune YOLOv11 on your dataset, reducing training time:
python train.py --weights yolov11-pretrained.pt --data my_dataset.yaml

Inference with YOLOv11
Once your YOLOv11 model is trained, it’s time to put it to work by running inference on images, videos, or live camera feeds.
Running Inference on Images
To perform inference on a single image, use the inference script provided in the YOLOv11 repository:
python detect.py --weights yolov11.pt --img 640 --source path/to/image.jpg--weights: Path to the trained YOLOv11 weights.--img: Input image size (e.g., 640×640).--source: Path to the image file.
Running Inference on Videos
To process video files, specify the video path as the source:
python detect.py --weights yolov11.pt --img 640 --source path/to/video.mp4The output will display the detected objects with bounding boxes, class labels, and confidence scores. Results can be saved by adding the --save-txt and --save-img flags.
Real-Time Inference
For live video feeds, such as from a webcam:
python detect.py --weights yolov11.pt --source 0
Here, --source 0 specifies the default camera. Real-time inference requires high computational efficiency, and YOLOv11’s architecture ensures smooth performance on capable hardware.
Optimizing Inference Speed
If inference speed is a priority, consider these optimizations:
- Use a Smaller Model: Choose a lightweight YOLOv11 variant (e.g., YOLOv11-tiny).
- FP16 Precision: Enable mixed-precision inference for faster computations.
python detect.py --weights yolov11.pt --img 640 --source path/to/image.jpg --half- ONNX Conversion: Convert YOLOv11 to ONNX or TensorRT for deployment on specialized hardware.

Advanced Topics
Fine-Tuning and Model Optimization
Fine-tuning YOLOv11 involves retraining on domain-specific datasets to improve accuracy. Adjusting hyperparameters such as learning rate decay and dropout rates can enhance the model’s generalization.
Additionally, pruning and quantization techniques reduce model size and improve inference speed without significant loss in accuracy.
Deployment on Edge Devices
YOLOv11 is optimized for deployment on edge devices like NVIDIA Jetson Nano, Raspberry Pi, or Coral TPU. To deploy:
Convert the trained model to ONNX:
python export.py --weights yolov11.pt --img 640 --batch 1
Optimize the ONNX model with TensorRT:
trtexec --onnx=model.onnx --saveEngine=model.engine
Load the model on the edge device and run inference.
Integrating YOLOv11 into Larger Systems
YOLOv11 can be integrated into end-to-end systems using APIs like Flask, FastAPI, or Django. For example:
- Create a REST API endpoint for inference.
- Load YOLOv11 model weights in the server script.
- Process incoming images and return detection results in JSON format.
Common Challenges and Troubleshooting
Overfitting and Underfitting
- Overfitting: Use data augmentation techniques (e.g., flipping, scaling) and apply regularization.
- Underfitting: Increase model complexity or training duration and ensure the dataset represents real-world scenarios.
Debugging Training Errors
- Training Diverges: Check learning rates and reduce batch size.
- No Detections: Verify dataset annotations and labels.
- Low Accuracy: Adjust anchors or enable multi-scale training.
Performance Tuning
- Use gradient accumulation for large datasets.
- Leverage distributed training across multiple GPUs.
YOLOv11 in Practice
Case Studies
1. Autonomous Drones:
A drone company utilized YOLOv11 to identify objects mid-flight, enabling collision avoidance and object delivery. The model’s real-time detection capabilities allowed for seamless operation in dynamic environments.
2. Retail Analytics:
YOLOv11 was integrated into a retail analytics platform to monitor customer movement and inventory levels, offering valuable insights to store managers.
Open-Source Implementations
Explore projects on GitHub that extend YOLOv11’s functionalities, such as multi-camera tracking or object counting.
Future of Object Detection and YOLO
As computer vision evolves, trends like self-supervised learning, transformer-based architectures, and multimodal integration (combining vision with language) will shape the field. YOLOv11’s innovations position it as a key player in this trajectory, setting a strong foundation for future advancements.
Potential improvements include:
- More energy-efficient models.
- Better handling of edge cases, such as occlusions or adversarial attacks.
- Integration with augmented and virtual reality systems.

Conclusion
YOLOv11 represents a significant leap in object detection technology, combining state-of-the-art accuracy with unparalleled speed. Its versatility makes it suitable for a wide range of applications, from real-time surveillance to embedded systems.
This guide has walked you through every aspect of using YOLOv11, from setup and training to deployment and optimization. As you implement YOLOv11 in your projects, experiment with its advanced features and push the boundaries of what’s possible in computer vision.
The future is bright for object detection, and with YOLOv11, you’re well-equipped to be part of this exciting journey. Happy coding!








