Introduction
For nearly a decade, the YOLO (You Only Look Once) family has defined what real-time computer vision means. From the revolutionary YOLOv1 in 2015 to increasingly efficient and accurate successors, each generation has pushed the boundary between speed, accuracy, and deployability.
In 2026, a new milestone arrived.
YOLO26 is not just another incremental upgrade, it represents a fundamental redesign of how object detection systems are trained, optimized, and deployed, especially for edge devices and real-world AI systems.
Built with an edge-first philosophy, YOLO26 introduces end-to-end detection without traditional post-processing, improved stability during training, and multi-task vision capabilities, making it one of the most practical computer vision models ever released.
This article explores:
✅ The evolution leading to YOLO26
✅ Architecture innovations
✅ Why NMS-free detection matters
✅ Performance improvements
✅ Real-world applications
✅ How developers can use YOLO26 today
✅ The future of vision AI
The Journey to YOLO26
Object detection historically struggled with a difficult trade-off:
Faster models sacrificed accuracy
Accurate models required heavy computation
Real-time deployment remained difficult
Earlier YOLO versions gradually solved these problems:
YOLOv5–v8 improved usability and modular training
YOLOv9–v11 introduced smarter gradient learning and efficiency improvements
YOLOv10 began moving toward end-to-end detection pipelines
YOLO26 completes this transition.
Instead of patching limitations with additional heuristics, it redesigns the pipeline itself.
Research analyzing the model highlights that YOLO26 establishes a new efficiency–accuracy balance while outperforming many previous detectors in both speed and precision.

What Is YOLO26?
YOLO26 is a real-time, multi-task computer vision model optimized for:
Object detection
Instance segmentation
Pose estimation
Tracking
Classification
Unlike earlier detectors, YOLO26 is designed primarily for edge deployment, meaning it runs efficiently on:
CPUs
Mobile devices
Embedded systems
Robotics hardware
Jetson and ARM platforms
The model supports scalable sizes, allowing developers to choose between lightweight and high-accuracy configurations depending on hardware constraints.
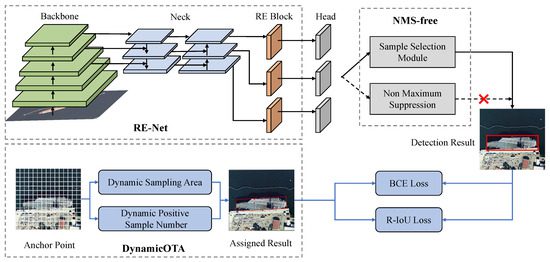
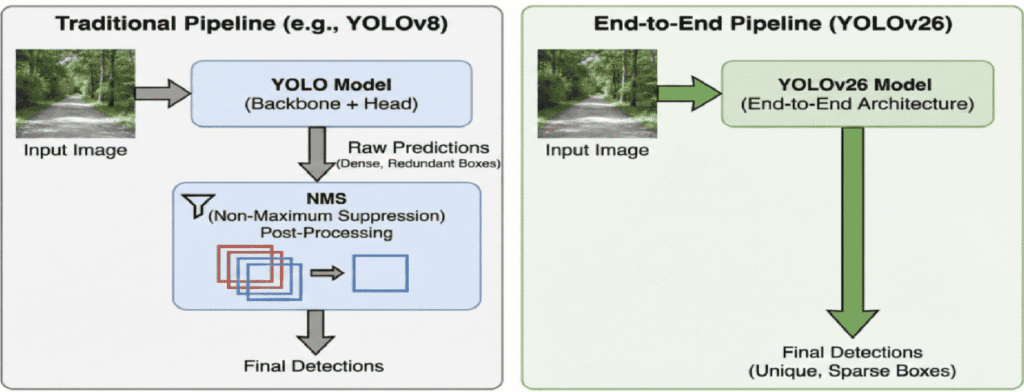
The Biggest Breakthrough: NMS-Free Detection
The Problem with Traditional YOLO
Previous YOLO models relied on Non-Maximum Suppression (NMS).
NMS removes duplicate bounding boxes after prediction — but it introduces problems:
Extra latency
Hyperparameter tuning complexity
Instability in crowded scenes
Deployment inconsistencies
YOLO26 Solution
YOLO26 eliminates NMS entirely.
Instead, detection becomes fully end-to-end — predictions are learned directly during training rather than filtered afterward.
This change:
Reduces inference time
Simplifies deployment
Improves consistency across devices
Researchers note that removing heuristic post-processing resolves long-standing latency vs. precision trade-offs in object detection systems.
Key Architectural Innovations
YOLO26 introduces several new mechanisms.
1. Progressive Loss Balancing (ProgLoss)
Training object detectors often suffers from unstable gradients.
ProgLoss dynamically adjusts learning emphasis during training, allowing:
Faster convergence
Improved generalization
Stable optimization on small datasets
2. Small-Target-Aware Label Assignment (STAL)
Small objects are traditionally difficult to detect.
STAL improves label assignment by prioritizing tiny and distant objects — critical for:
Surveillance
Drone imagery
Autonomous driving
Medical imaging
3. MuSGD Optimizer
Inspired by optimization strategies used in large AI models, MuSGD improves:
Training stability
Quantization readiness
Low-precision deployment
4. Removal of Distribution Focal Loss (DFL)
Earlier YOLO versions used complex bounding box regression losses.
YOLO26 simplifies this pipeline, enabling:
Easier export to ONNX/TensorRT
Faster inference
Reduced memory overhead
Where YOLOv1 Fell Short, and Why That’s Important
YOLOv1’s limitations weren’t accidental; they revealed deep insights.
Small Objects
Grid resolution limited detection granularity
Small objects often disappeared within grid cells
Crowded Scenes
One object class prediction per cell
Overlapping objects confused the model
Localization Precision
Coarse bounding box predictions
Lower IoU scores than region-based methods
Each weakness became a research question that drove YOLOv2, YOLOv3, and beyond.
Edge-First Design Philosophy
One of YOLO26’s defining goals is predictable latency.
Traditional models were GPU-centric.
YOLO26 focuses on:
CPU acceleration
Embedded inference
Low-power AI devices
Benchmarks show significant CPU inference improvements and reliable performance even without GPUs.
This shift makes AI accessible beyond data centers.
Performance Improvements
YOLO26 improves across three critical axes:
Speed
Faster inference due to NMS removal
Reduced computational overhead
Accuracy
Better small-object detection
Improved dense-scene performance
Efficiency
Smaller models with higher mAP
Stable quantization for edge deployment
Studies comparing YOLO26 with earlier generations highlight superior deployment versatility and efficiency across edge hardware platforms.
Multi-Task Vision: One Model, Many Tasks
YOLO26 moves toward unified vision AI.
Supported tasks include:
Detection
Segmentation
Pose estimation
Tracking
Oriented bounding boxes
This reduces the need to maintain separate models for each task, simplifying production pipelines.
Real-World Applications
YOLO26 unlocks new possibilities across industries.
Autonomous Systems
Robots navigating dynamic environments
Drone inspection systems
Smart Cities
Traffic monitoring
Crowd analysis
Security automation
Healthcare
Real-time medical imaging assistance
Surgical instrument tracking
Manufacturing
Defect detection
Quality assurance automation
Retail & Logistics
Shelf analytics
Warehouse automation
Because it runs efficiently on edge devices, processing can happen locally — improving privacy and reducing cloud costs.
Developer Experience
One reason YOLO became dominant is usability — and YOLO26 continues that tradition.
Developers benefit from:
Simple training pipelines
Export to multiple runtimes
Easy fine-tuning
Real-time video inference
Typical workflow:
Prepare dataset
Train using pretrained weights
Export model
Deploy on edge device
No complex post-processing configuration required.
YOLO26 vs Previous YOLO Versions
| Feature | YOLOv8–11 | YOLO26 |
|---|---|---|
| NMS Required | Yes | No |
| Edge Optimization | Moderate | Native |
| Multi-Task Support | Partial | Unified |
| Training Stability | Good | Improved |
| Deployment Complexity | Medium | Low |
YOLO26 marks the transition from fast detectors to deployment-ready AI systems.
Challenges and Limitations
Despite improvements, challenges remain:
Dense overlapping scenes still difficult
Training large datasets remains compute-heavy
Open-vocabulary detection is limited
Transformer integration still evolving
Future models may combine YOLO efficiency with foundation-model reasoning.
The Future After YOLO26
YOLO26 signals a broader shift in computer vision:
👉 From GPU-centric AI → Edge AI
👉 From pipelines → End-to-end learning
👉 From single-task → unified perception systems
Future developments may include:
Vision-language integration
Self-supervised detection
On-device continual learning
Autonomous AI perception stacks
Conclusion
YOLO26 is more than a version update.
It represents a philosophical shift in computer vision engineering — simplifying architecture while improving real-world performance.
By removing legacy bottlenecks like NMS, introducing smarter training strategies, and prioritizing edge deployment, YOLO26 brings AI closer to where it matters most: the real world.
As AI moves beyond research labs into everyday devices, models like YOLO26 will define the next generation of intelligent systems.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.