



Introduction
Modern LLMs are no longer curiosities. They are front-line infrastructure. Search, coding, support, analytics, and creative work now route through models that read, reason, and act at scale. The winners are not defined by parameter counts alone. They win by running a disciplined loop: curate better data, choose architectures that fit constraints, train and align with care, then measure what actually matters in production.
This guide takes a systems view. We start with data because quality and coverage set your ceiling. We examine architectures, dense, MoE, and hybrid, through the lens of latency, cost, and capability. We map training pipelines from pretraining to instruction tuning and preference optimization. Then we move to inference, where throughput, quantization, and retrieval determine user experience. Finally, we treat evaluation as an operations function, not a leaderboard hobby.
The stance is practical and progressive. Open ecosystems beat silos when privacy and licensing are respected. Safety is a product requirement, not a press release. Efficiency is climate policy by another name. And yes, you can have rigor without slowing down—profilers and ablation tables are cheaper than outages.
If you build LLM products, this playbook shows the levers that move outcomes: what to collect, what to train, what to serve, and what to measure. If you are upgrading an existing stack, you will find drop-in patterns for long context, tool use, RAG, and online evaluation. Along the way, we keep the tone clear and the checklists blunt. The goal is simple: ship models that are useful, truthful, and affordable. If we crack a joke, it is only to keep the graphs awake.
Why LLMs Win: A Systems View
LLMs work because three flywheels reinforce each other:
Data scale and diversity improve priors and generalization.
Architecture turns compute into capability with efficient inductive biases and memory.
Training pipelines exploit hardware at scale while aligning models with human preferences.
Treat an LLM like an end-to-end system. Inputs are tokens and tools. Levers are data quality, architecture choices, and training schedules. Outputs are accuracy, latency, safety, and cost. Modern teams iterate the entire loop, not just model weights.

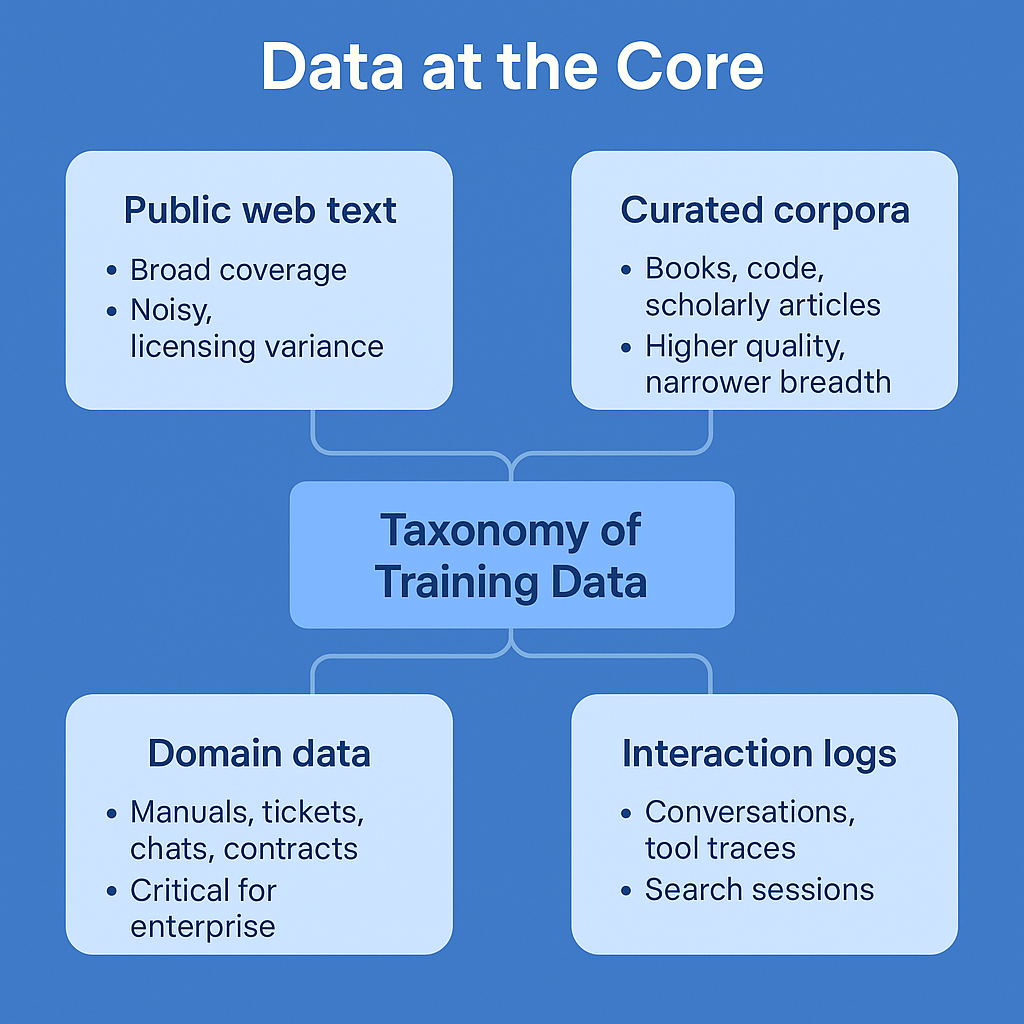
Data at the Core
Taxonomy of Training Data
Public web text: broad coverage, noisy, licensing variance.
Curated corpora: books, code, scholarly articles. Higher quality, narrower breadth.
Domain data: manuals, tickets, chats, contracts, EMRs, financial filings. Critical for enterprise.
Interaction logs: conversations, tool traces, search sessions. Valuable for post-training.
Synthetic data: self-play, bootstrapped explanations, diverse paraphrases. A control knob for coverage.
A strong base model uses large, diverse pretraining data to learn general language. Domain excellence comes later by targeted post-training and retrieval.
Quality, Diversity, and Coverage
Quality: correctness, coherence, completeness.
Diversity: genres, dialects, domains, styles.
Coverage: topics, edge cases, rare entities.
Use weighted sampling: upsample scarce but valuable genres (math solutions, code, procedural text) and downsample low-value boilerplate or spam. Maintain topic taxonomies and measure representation. Apply entropy-based and perplexity-based heuristics to approximate difficulty and novelty.
Cleaning, Deduplication, and Contamination Control
Cleaning: strip boilerplate, normalize Unicode, remove trackers, fix broken markup.
Deduplication: MinHash/LSH or embedding similarity with thresholds per domain. Keep one high-quality copy.
Contamination: guard against train-test leakage. Maintain blocklists of eval items, crawl timestamps, and near-duplicate checks. Log provenance to answer “where did a token come from?”
Tokenization and Vocabulary Strategy
Modern systems favor byte-level BPE or Unigram tokenizers with multilingual coverage. Design goals:
Compact rare scripts without ballooning vocab size.
Stable handling of punctuation, numerals, code.
Low token inflation for domain text (math, legal, code).
Evaluate tokenization cost per domain. A small change in tokenizer can shift context costs and training stability.
Long-Context and Structured Data
If you expect 128k+ tokens:
Train with long-sequence curricula and appropriate positional encodings.
Include structured data formats: JSON, XML, tables, logs.
Teach format adherence with schema-constrained generation and few-shot exemplars.
Synthetic Data and Data Flywheels
Synthetic data fills gaps:
Explanations and rationales raise faithfulness on reasoning tasks.
Contrastive pairs improve refusal and safety boundaries.
Counterfactuals stress-test reasoning and reduce shortcut learning.
Build a data flywheel: deploy → collect user interactions and failure cases → bootstrap fixes with synthetic data → validate → retrain.
Privacy, Compliance, and Licensing
Maintain license metadata per sample.
Apply PII scrubbing with layered detectors and human review for high-risk domains.
Support data subject requests by tracking provenance and retention windows.
Evaluation Datasets: Building a Trustworthy Yardstick
Design evals that mirror your reality:
Static capability: language understanding, reasoning, coding, math, multilinguality.
Domain-specific: your policies, formats, product docs.
Live online: shadow traffic, canary prompts, counterfactual probes.
Rotate evals and guard against overfitting. Keep a sealed test set.
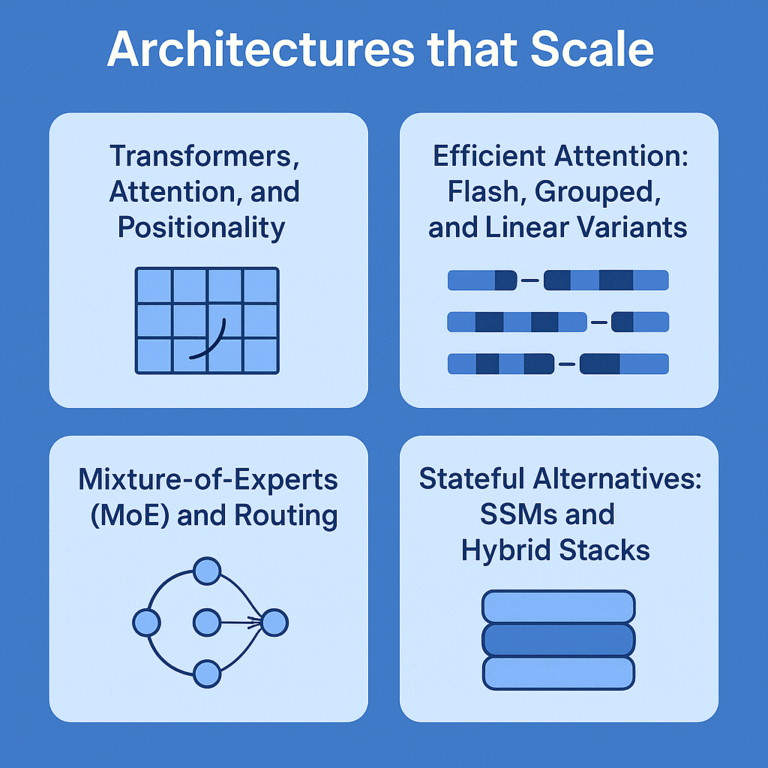
Architectures that Scale
Transformers, Attention, and Positionality
The baseline remains decoder-only Transformers with causal attention. Key components:
Multi-head attention for distributed representation.
Feed-forward networks with gated variants (GEGLU/Swish-Gated) for expressivity.
LayerNorm/RMSNorm for stability.
Positional encodings to inject order.
Efficient Attention: Flash, Grouped, and Linear Variants
FlashAttention: IO-aware kernels, exact attention with better memory locality.
Multi-Query or Grouped-Query Attention: fewer key/value heads, faster decoding at minimal quality loss.
Linear attention and kernel tricks: useful for very long sequences, but trade off exactness.
Extending Context: RoPE, ALiBi, and Extrapolation Tricks
RoPE (rotary embeddings): strong default for long-context pretraining.
ALiBi: attention biasing that scales context without retraining positional tables.
NTK/rope scaling and YaRN-style continuation can extend effective context, but always validate on long-context evals.
Segmented caches and windowed attention can reduce quadratic cost at inference.
Mixture-of-Experts (MoE) and Routing
MoE increases parameter count with limited compute per token:
Top-k routing (k=1 or 2) activates a subset of experts.
Balancing losses prevent expert collapse.
Expert parallelism is a new dimension in distributed training.
Gains: higher capacity at similar FLOPs. Costs: complexity, instability risk, serving challenges.
Stateful Alternatives: SSMs and Hybrid Stacks
Structured State Space Models (SSMs) and successor families offer linear-time sequence modeling. Hybrids combine SSM blocks for memory with attention for flexible retrieval. Use cases: very long sequences, streaming.
Multimodality: Text+Vision+Audio
Modern assistants blend modalities:
Vision encoders (ViT/CLIP-like) project images into token streams.
Audio encoders/decoders handle ASR and TTS.
Fusion strategies: early fusion via learned adaptors, or late fusion via tool calls.
Tool Use, Function Calling, and Agents
Teach models to call functions with JSON arguments. Provide tool specs during training and instruction tuning. For agents:
Planner-solver loop with self-critique.
Retrieval and structured memory for grounding.
Safety governors wrapping tool execution.
Training at Scale
Objectives: Next-Token, UL2-style Mixtures, and Instruction Phases
Pretraining: next-token prediction with masked spans mixed in for robustness.
SFT (Supervised Fine-Tuning): instruction following from high-quality exemplars.
Preference optimization: RLHF, RLAIF, or DPO to align outputs to human preferences without policy collapse.
Scaling Laws and Budgeting: Data vs Parameters vs Compute
Follow compute-optimal recipes:
Balance parameters and tokens.
If you cannot increase compute, spend it on more tokens before adding parameters.
Target 10–20+ tokens per parameter as a rough planning anchor for general-purpose LLMs. Validate with pilots.
Distributed Training: ZeRO, TP/PP/DP, Checkpointing
Data Parallel (DP) for throughput.
Tensor Parallel (TP) splits matrices across devices.
Pipeline Parallel (PP) partitions layers.
ZeRO stages shard optimizer states and gradients.
Activation checkpointing trades compute for memory.
Use fully-sharded training for very large models. Test for deadlocks and optimizer state corruption early.
Optimizers, Schedules, and Mixed Precision
AdamW/Decoupled weight decay is still standard.
Adafactor reduces memory footprint.
Use cosine decay with warmup.
Train with BF16 or FP16 autocast. Keep FP32 master weights.
Gradient clipping protects against exploding updates.
Curriculum and Data Sampling
Start with easier and shorter sequences.
Ramp to longer contexts and harder domains.
Temperature-based sampling over source distributions prevents over-fitting to frequent domains.
Instruction Tuning, RLHF, RLAIF, and DPO
SFT establishes instruction following.
RLHF: train a reward model on human preferences then optimize a policy with PPO or variants.
RLAIF: replace or augment human labels with model-assisted feedback.
DPO: direct policy optimization without an explicit reward model, using chosen vs rejected pairs. Simpler pipeline, strong results.
Maintain safety preference datasets to encode refusal boundaries, tone, and harmlessness.
Safety, Red-Teaming, and Guardrails
Pretrain with toxic-aware filters and policy exemplars.
Post-train with safety-specific preference data.
Red-team using jailbreak taxonomies and tool-aware adversarial prompts.
Wrap models with guardrails: content classifiers, tool allowlists, and rate limiting.

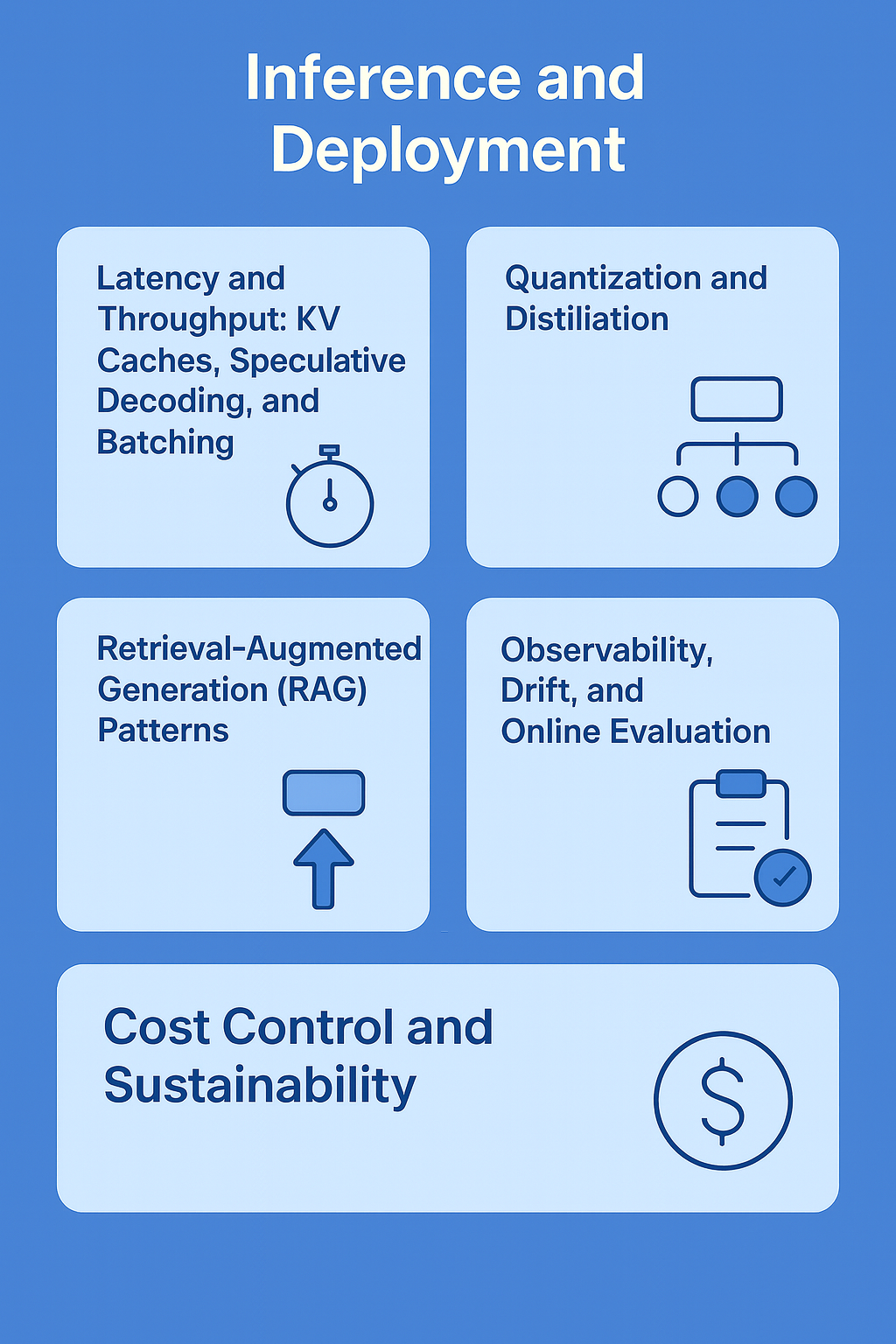
Inference and Deployment
Latency and Throughput: KV Caches, Speculative Decoding, and Batching
KV cache reuse accelerates streaming. Pin cache on GPU for hot sessions.
Speculative decoding: draft small model proposes tokens, large model verifies. Cuts latency at similar quality.
Batching: dynamic and continuous batching maximize GPU utilization.
Paged attention and tensorized decode kernels stabilize performance for long contexts.
Quantization and Distillation
Post-training quantization: INT8/INT4 with outlier handling (e.g., AWQ) for large throughput gains.
QAT improves quality at low bits when you can retrain.
Distillation: train a smaller student on teacher outputs and rationales. Keep tool-use traces so students inherit abilities.
Retrieval-Augmented Generation (RAG) Patterns
Index design: hybrid dense+lexical search.
Chunking: size by semantic boundaries; overlap for continuity.
Citations: ask model to ground answers in retrieved spans.
Iterative RAG: retrieve → generate questions → retrieve again for gaps.
Freshness: hot indexes for daily updates; cold stores for archives.
Observability, Drift, and Online Evaluation
Track latency P50/P95, token/s, context length, cache hit rates.
Monitor content safety, hallucination proxies, and grounding coverage.
Run A/B tests on shadow traffic.
Alert on domain drift and tool failure.
Cost Control and Sustainability
Prefer smaller models with RAG for many workloads.
Use quantized serving and GPU sharing.
Schedule off-peak batches for low-priority jobs.
Profile to remove hidden bottlenecks (CPU tokenization, serializer overhead, PCIe transfers).
Evaluation that Matters
Capability Benchmarks
Core language: comprehension, summarization, translation.
Reasoning: math, logic, code generation/debugging.
Long-context: retrieval and fidelity across 32k–256k tokens.
Multilingual: balanced across major families and scripts.
Multimodal: OCR-like tasks, charts, UI screenshots, diagrams.
Robustness, Security, and Safety Tests
Adversarial prompts and jailbreak suites.
Grounding checks: compare citations to claims.
Tool safety: simulate malicious tool outputs.
Privacy: memorization probes for sensitive strings.
Business-Aligned Metrics
Task success and first-pass yield for your flows.
Resolution time and deflection rate in support.
Precision@k and faithfulness for RAG.
Human time saved for internal copilots.
Case Blueprints
Building a Domain LLM
Goal: an assistant fluent in your policies, forms, and SOPs.
Steps:
Curate domain corpus. Add manuals, SOPs, tickets, emails, schemas.
Tokenization audit: ensure low inflation for domain jargon.
Base model selection: start with a robust 7B–13B or 70B depending on latency budget.
RAG first: build hybrid retrieval and document governance.
SFT: teach formats, references, and refusal boundaries.
Preference alignment: DPO on realistic scenarios.
Safety: add domain-specific refusals and PII filters.
Evaluate: task-level metrics and live canaries.
Iterate via data flywheel.
Common traps: overfitting to small SFT sets, relying on model memory instead of retrieval, neglecting citation fidelity.
Long-Context QA Assistant
Goal: handle 128k+ tokens of specs and threads.
Key moves:
Train or fine-tune with long sequences and RoPE/ALiBi scaling.
Use paged attention and cache partitioning for serving.
Index documents anyway. Long context is not a retrieval replacement.
Evaluate on needle-in-a-haystack and cross-doc grounding.
Multimodal Customer Support
Goal: interpret screenshots, logs, and text.
Design:
Vision encoder feeding token adaptors into the LLM.
Tooling for ticket retrieval, KB search, RMA creation.
SFT on screenshot+text → structured action dialogues.
Safety: guard against sensitive screenshot content leaks.
The Road Ahead
Long-horizon memory: hybrids that persist across sessions with compact summaries.
Smarter tool ecosystems: models that plan, verify, and recover from tool failures.
Energy-aware training: greener kernels, better utilization, and adaptive precision.
Truthfulness: tighter coupling of generation with retrieval and verification.
Personalization under privacy: federated fine-tuning, on-device adapters, synthetic augmentation.
Checklists and Playbooks
Data Curation Checklist
Source diversity map with target coverage goals
Cleaning, dedup, contamination logs
Tokenization audit per domain
PII and license metadata attached per sample
Synthetic data plan with evaluation loop
Eval sets locked and monitored for leakage
Architecture Checklist
Attention kernel choice validated on target hardware
Positional strategy aligned with context goals
MoE or dense trade-off decided with serving plan
Multimodal adaptors, if needed
Function calling API spec and tool sandboxing
Training Checklist
Warmup and schedule selected with batch/seq plans
Mixed precision, gradient clipping, and checkpointing
ZeRO/TP/PP plans tested at small scale
SFT datasets with schema adherence examples
DPO/RLHF preferences including safety and refusals
Inference Checklist
KV cache and batching verified under load
Quantization A/B vs full-precision
Speculative decoding configs tuned
RAG grounding with citation scoring
Observability dashboards and alerts
Evaluation Checklist
Capability suite across your target tasks
Safety and jailbreak probes
Business metrics wired into CI/CD
Drift detection and weekly scorecards
Example Release Process
Data freeze with contamination audit.
Training dry run at 5% scale to validate memory, grads, and loss curves.
Full run with periodic checkpoints.
SFT with structured tasks.
DPO using curated pairs covering helpfulness and safety.
Offline eval on capability and safety suites.
Canary deploy to low-risk users with shadow logging.
A/B rollout with guardrails.
Data flywheel update and next cycle plan.
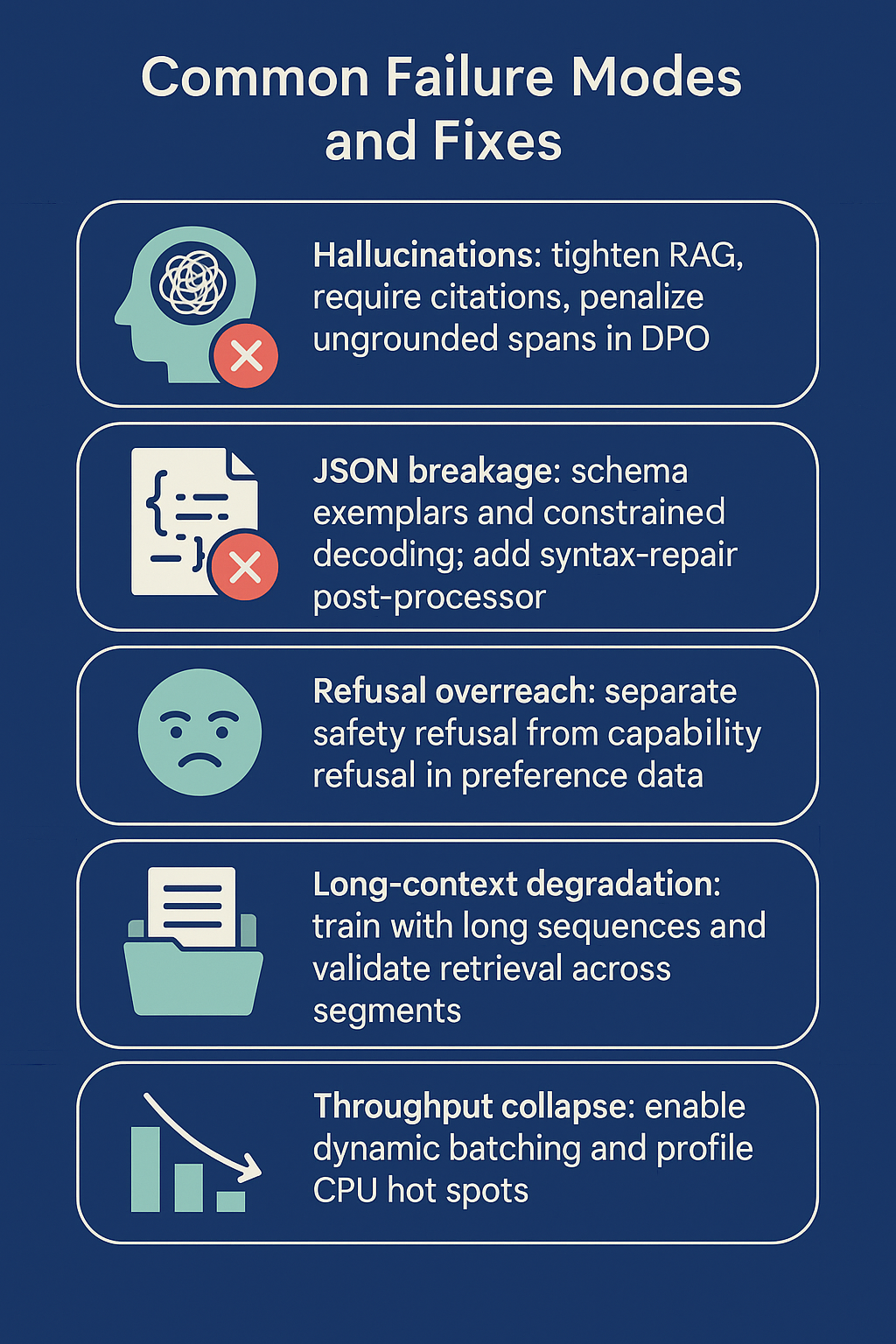
Common Failure Modes and Fixes
Hallucinations: tighten RAG, require citations, penalize ungrounded spans in DPO.
JSON breakage: schema exemplars and constrained decoding; add syntax-repair post-processor.
Refusal overreach: separate safety refusal from capability refusal in preference data.
Long-context degradation: train with long sequences and validate retrieval across segments.
Throughput collapse: enable dynamic batching and profile CPU hot spots.
Conclusion
Modern LLMs win with disciplined data curation, pragmatic architecture, and robust training. The best teams run a loop: deploy, observe, collect, synthesize, align, and redeploy. Retrieval grounds truth. Preference optimization shapes behavior. Quantization and batching deliver scale. Above all, evaluation must be continuous and business-aligned.
Use the checklists to operationalize. Start small, instrument everything, and iterate the flywheel.








