


Introduction
Before YOLO, computers didn’t see the world the way humans do. They inspected it slowly, cautiously, one object proposal at a time. Object detection worked, but it was fragmented, computationally expensive, and far from real time.
Then, in 2015, a single paper changed everything.
“You Only Look Once: Unified, Real-Time Object Detection” by Joseph Redmon et al. introduced YOLOv1, a model that redefined how machines perceive images. It wasn’t just an incremental improvement, it was a conceptual revolution.
This is the story of how YOLOv1 was born, how it worked, and why its impact still echoes across modern computer vision systems today.
Object Detection Before YOLO: A Fragmented World
Before YOLOv1, object detection research was dominated by complex pipelines stitched together from multiple independent components. Each component worked reasonably well on its own, but the overall system was fragile, slow, and difficult to optimize.
The Classical Detection Pipeline
A typical object detection system before 2015 looked like this:
Hand-crafted or heuristic-based region proposal
Selective Search
Edge Boxes
Sliding windows (earlier methods)
Feature extraction
CNN features (AlexNet, VGG, etc.)
Run separately on each proposed region
Classification
SVMs or softmax classifiers
One classifier per region
Bounding box regression
Fine-tuning box coordinates post-classification
Each stage was trained independently, often with different objectives.
Why This Was a Problem
Redundant computation
The same image features were recomputed hundreds of times.No global context
The model never truly “saw” the full image at once.Pipeline fragility
Errors in region proposals could never be recovered downstream.Poor real-time performance
Even Fast R-CNN struggled to exceed a few FPS.
Object detection worked, but it felt like a workaround, not a clean solution.
The YOLO Philosophy: Detection as a Single Learning Problem
YOLOv1 challenged the dominant assumption that object detection must be a multi-stage problem.
Instead, it asked a radical question:
Why not predict everything at once, directly from pixels?
A Conceptual Shift
YOLO reframed object detection as:
A single regression problem from image pixels to bounding boxes and class probabilities.
This meant:
No region proposals
No sliding windows
No separate classifiers
No post-hoc stitching
Just one neural network, trained end-to-end.
Why This Matters
This shift:
Simplified the learning objective
Reduced engineering complexity
Allowed gradients to flow across the entire detection task
Enabled true real-time inference
YOLO didn’t just optimize detection, it redefined what detection was.
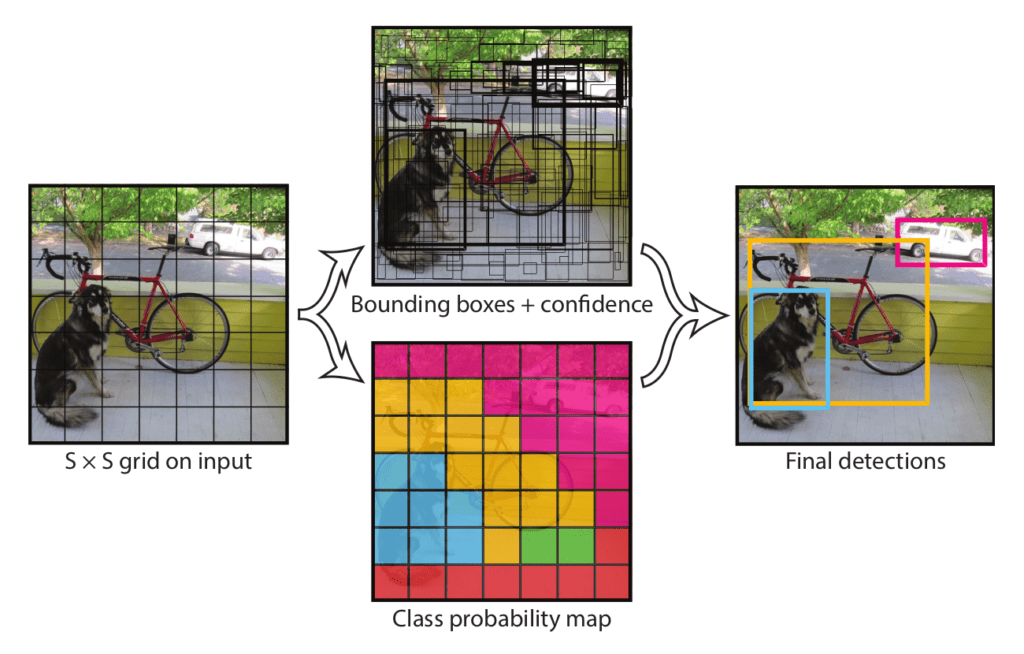
How YOLOv1 Works: A New Visual Grammar
YOLOv1 introduced a structured way for neural networks to “describe” an image.
Grid-Based Responsibility Assignment
The image is divided into an S × S grid (commonly 7 × 7).
Each grid cell:
Is responsible for objects whose center lies within it
Predicts bounding boxes and class probabilities
This created a spatial prior that helped the network reason about where objects tend to appear.
Bounding Box Prediction Details
Each grid cell predicts B bounding boxes, where each box consists of:
x, y → center coordinates (relative to the grid cell)
w, h → width and height (relative to the image)
confidence score
The confidence score encodes:
Pr(object) × IoU(predicted box, ground truth)
This was clever, it forced the network to jointly reason about objectness and localization quality.
Class Prediction Strategy
Instead of predicting classes per bounding box, YOLOv1 predicted:
One set of class probabilities per grid cell
This reduced complexity but introduced limitations in crowded scenes, a trade-off YOLOv1 knowingly accepted.
YOLOv1 Architecture: Designed for Global Reasoning
YOLOv1’s network architecture was intentionally designed to capture global image context.
Architecture Breakdown
24 convolutional layers
2 fully connected layers
Inspired by GoogLeNet (but simpler)
Pretrained on ImageNet classification
The final fully connected layers allowed YOLO to:
Combine spatially distant features
Understand object relationships
Avoid false positives caused by local texture patterns
Why Global Context Matters
Traditional detectors often mistook:
Shadows for objects
Textures for meaningful regions
YOLO’s global reasoning reduced these errors by understanding the scene as a whole.
The YOLOv1 Loss Function: Balancing Competing Objectives
Training YOLOv1 required solving a delicate optimization problem.
Multi-Part Loss Components
YOLOv1’s loss function combined:
Localization loss
Errors in x, y, w, h
Heavily weighted to prioritize accurate boxes
Confidence loss
Penalized incorrect objectness predictions
Classification loss
Penalized wrong class predictions
Smart Design Choices
Higher weight for bounding box regression
Lower weight for background confidence
Square root applied to width and height to stabilize gradients
These design choices directly influenced how future detection losses were built.
Speed vs Accuracy: A Conscious Design Trade-Off
YOLOv1 was explicit about its priorities.
YOLO’s Position
Slightly worse localization is acceptable if it enables real-time vision.
Performance Impact
YOLOv1 ran an order of magnitude faster than competing detectors
Enabled deployment on:
Live camera feeds
Robotics systems
Embedded devices (with Fast YOLO)
This trade-off reshaped how researchers evaluated detection systems, not just by accuracy, but by usability.
Where YOLOv1 Fell Short, and Why That’s Important
YOLOv1’s limitations weren’t accidental; they revealed deep insights.
Small Objects
Grid resolution limited detection granularity
Small objects often disappeared within grid cells
Crowded Scenes
One object class prediction per cell
Overlapping objects confused the model
Localization Precision
Coarse bounding box predictions
Lower IoU scores than region-based methods
Each weakness became a research question that drove YOLOv2, YOLOv3, and beyond.
Why YOLOv1 Changed Computer Vision Forever
YOLOv1 didn’t just introduce a model, it introduced a mindset.
End-to-End Learning as a Principle
Detection systems became:
Unified
Differentiable
Easier to deploy and optimize
Real-Time as a First-Class Metric
After YOLO:
Speed was no longer optional
Real-time inference became an expectation
A Blueprint for Future Detectors
Modern architectures, CNN-based and transformer-based alike, inherit YOLO’s core ideas:
Dense prediction
Single-pass inference
Deployment-aware design
Final Reflection: The Day Detection Became Vision
YOLOv1 marked the moment when object detection stopped being a patchwork of tricks and became a coherent vision system.
It taught the field that:
Seeing fast unlocks new realities
Simplicity scales
End-to-end learning changes how machines understand the world
YOLO didn’t just look once.
It made computer vision see differently forever.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.








