



Welcome to Mastering LLM Fine-Tuning: Data Strategies for Smarter AI – a comprehensive guide to transforming generic Large Language Models (LLMs) into specialized tools that solve real-world problems.
In the era of AI, LLMs like GPT-4 and LLaMA have revolutionized industries with their ability to generate text, analyze data, and even write code. But out of the box, these models are generalists – they lack the precision required for niche tasks like diagnosing rare diseases, detecting financial fraud, or drafting legal contracts. This is where fine-tuning comes in.
Why This Series?
Fine-tuning an LLM is more than just a technical exercise – it’s a strategic process that hinges on data quality, ethical practices, and computational efficiency. Most guides focus on code snippets or theoretical concepts, but they often skip the why and how of data curation, leaving models prone to bias, inefficiency, or irrelevance.
In this series, you’ll learn:
How to source, clean, and augment data for domain-specific tasks.
Techniques to mitigate bias and ensure compliance with global regulations.
Advanced strategies like federated learning and RLHF (Reinforcement Learning from Human Feedback).
Real-world case studies from healthcare, finance, and legal industries.
Whether you’re an ML engineer, data scientist, or AI enthusiast, this guide will equip you with actionable insights to build LLMs that are smarter, safer, and scalable.
LLM Fine-Tuning Basics
What is Fine-Tuning?
Fine-tuning adapts a pre-trained LLM (like GPT-4 or LLaMA) to specialize in a specific task by training it on a smaller, domain-specific dataset.
Key Concepts:
Transfer Learning: Leveraging knowledge from general pre-training to solve niche problems.
Catastrophic Forgetting: A risk where the model “forgets” general skills during fine-tuning. Mitigated via techniques like elastic weight consolidation.
Technical Deep Dive:
Fine-tuning updates model weights using backpropagation and gradient descent.
Loss functions (e.g., cross-entropy) are tailored to the task (classification, generation, etc.).
Example:
A pre-trained LLM achieves 70% accuracy on medical QA tasks. After fine-tuning on 10,000 annotated clinical notes, accuracy jumps to 92%.
Visual:

Why Fine-Tune?
Accuracy: Achieve higher performance on niche tasks (e.g., detecting sarcasm in customer feedback).
Efficiency: Avoid training models from scratch.
Customization: Align outputs with business needs (e.g., brand-specific tone).
When to Fine-Tune?
✅ Low-resource domains (e.g., rare languages).
✅ Compliance-heavy industries (e.g., healthcare, finance).
✅ Unique use cases (e.g., generating code for legacy systems).
Fine-Tuning Methods
1. Full Fine-Tuning
Updates all model weights.
Requires heavy computational resources (e.g., GPU clusters).
2. Parameter-Efficient Methods
LoRA (Low-Rank Adaptation): Updates only low-rank matrices, freezing most weights.
Adapters: Adds small trainable layers between transformer blocks.
3. Prompt Tuning
Trains soft prompts (continuous embeddings) instead of model weights.
| Method | Trainable Parameters | Compute Cost |
|---|---|---|
| Full Fine-Tuning | 100% | High |
| LoRA | 1-5% | Low |
| Prompt Tuning | <1% | Very Low |
Data Collection Strategies
Why Data Collection Matters
Fine-tuning success hinges on quality, diversity, and relevance of data. Poor data leads to hallucinations, bias, or poor generalization.
Key Data Sources
1. Public Datasets
Pros:
Low cost and quick access.
Broad coverage (e.g., Common Crawl).
Cons:
Noise (irrelevant or low-quality text).
Licensing restrictions (e.g., GDPR compliance).
Top Public Datasets for Fine-Tuning:
| Dataset | Domain | Size | Use Case |
|---|---|---|---|
| WikiText | General Language | 100M tokens | Language modeling baseline |
| PubMed | Healthcare | 30M abstracts | Medical QA |
| OpenLegal | Legal | 10K contracts | Contract analysis |
| COCO Captions | Vision + Text | 500K images | Multimodal tasks |

2. In-House Data
Sources:
Customer interactions: Chat logs, support tickets, emails.
Proprietary content: Technical manuals, internal wikis, code repositories.
Sensor/transaction data: For domain-specific tasks (e.g., IoT device logs).
Example:
A retail company uses customer reviews and product descriptions to fine-tune an LLM for personalized recommendations.
Best Practices:
Anonymization: Strip personally identifiable information (PII) using tools like Presidio.
Versioning: Track dataset iterations with tools like DVC.
3. Synthetic Data
When to Use:
Limited real-world data (e.g., rare medical conditions).
Privacy constraints (e.g., financial records).
Generation Methods:
Rule-Based Templates:
# Example: Generate synthetic legal clauses templates = [ "The {party} shall not {action} without written consent from {authority}.", "Any dispute arising under this contract shall be governed by {jurisdiction} law." ] keywords = { "party": ["Licensee", "Licensor"], "action": ["terminate", "modify", "transfer"], "authority": ["the Board", "the CEO"] }
LLM-Generated Content:
Use GPT-4, Claude, or Llama 3 to simulate data (e.g., fake customer queries).
Filter outputs for relevance and correctness.
Quality Control:
Human-in-the-Loop: Have experts review 10-20% of synthetic data.
Cross-Verification: Compare synthetic outputs with real-world samples using metrics like BLEU or ROUGE.
Data Source Comparison
| Aspect | Public Data | In-House Data | Synthetic Data |
|---|---|---|---|
| Cost | Low | Moderate | Low |
| Customization | Limited | High | High |
| Privacy Risk | Moderate | High | Low |
| Best For | Baseline tasks | Domain-specific use | Sensitive/scarce data |
Tools for Data Collection
| Tool | Function | Example Workflow |
|---|---|---|
| Hugging Face | Dataset hosting/curation | Load datasets.load_dataset("pubmed") |
| Snorkel | Weak supervision for labeling | Create labeling functions for FAQs |
| Gretel | Synthetic data generation | Generate synthetic patient records |
| Scale AI | Human labeling at scale | Annotate 10K support tickets |
Common Pitfalls & Fixes
Problem: Overfitting to small datasets.
Fix: Combine synthetic and real data + use regularization (e.g., dropout).Problem: Biased annotations.
Fix: Use multi-annotator consensus + tools like Label Studio.Problem: Data leakage (test data in training).
Fix: Strict train/test splits + hashing (e.g., Bloom filters).
Case Study: Financial Fraud Detection
Goal: Fine-tune an LLM to flag suspicious transaction descriptions.
Data Strategy:
Collected 1,000 labeled examples from historical fraud cases.
Generated 5,000 synthetic fraud patterns using rule-based templates (e.g., “Payment to {unknown_entity} for {ambiguous_service}”).
Augmented data with synonym replacement (e.g., “wire transfer” → “bank transfer”).
Result:
Precision improved from 65% → 91% on unseen transactions.
Ethical Sourcing & Bias Mitigation
Why Ethics and Bias Matter
Biased training data leads to unfair or harmful LLM outputs (e.g., discriminatory hiring recommendations, racial profiling in fraud detection). Ethical data practices are critical for compliance (GDPR, AI Act) and user trust.
Common Sources of Bias in LLM Data
| Bias Type | Description | Example |
|---|---|---|
| Sampling Bias | Under/over-representation of groups | Medical data skewed toward male patients |
| Labeling Bias | Annotator subjectivity | “Assertive” labeled as “aggressive” for women |
| Historical Bias | Past inequalities embedded in data | Loan denial data reflecting systemic racism |
| Linguistic Bias | Overrepresentation of dominant languages | 80% of training data in English |
Step-by-Step Bias Mitigation Framework
1. Audit Your Dataset
Tools:
Metrics to Track:
Disparate Impact Ratio:
(Selection Rate for Protected Group) / (Selection Rate for Majority Group)Accuracy Gaps: Performance differences across demographics.
Example:
An HR chatbot trained on biased hiring data shows a 25% lower recommendation rate for female candidates.
2. Debiasing Strategies
a) Pre-Processing (Data-Level)
Reweighting: Assign higher weights to underrepresented groups during training.
# Example: Adjust sample weights for imbalance from sklearn.utils.class_weight import compute_sample_weight sample_weights = compute_sample_weight(class_weight="balanced", y=train_labels)
Oversampling: Use techniques like SMOTE or NLPAug for text data.
b) In-Processing (Model-Level)
Adversarial Debiasing: Train the model to remove sensitive attributes (e.g., gender, race) from embeddings.

Fairness Constraints: Penalize biased predictions using libraries like TensorFlow Constrained Optimization.
c) Post-Processing (Output-Level)
Calibration: Adjust prediction thresholds for different groups.
Rejection Options: Flag uncertain or biased outputs for human review.
3. Diversify Data Sources
Language Diversity: Include low-resource languages (e.g., Swahili, Bengali) using datasets like OSCAR.
Demographic Diversity: Partner with global annotators via platforms like Appen or Remotasks.
Checklist for Diversity:
Include dialects (e.g., African American Vernacular English).
Balance gender/race in annotator teams.
Validate geographic representation.
Case Study: Mitigating Gender Bias in Resume Screening
Problem: An LLM for resume ranking favored male candidates in tech roles.
Solution:
Audit: Fairlearn revealed a 30% disparity in recommendation rates.
Debiasing:
Reweighting: Doubled the weight of female resumes.
Adversarial Training: Removed gender signals from embeddings.
Post-Processing: Adjusted score thresholds for female candidates.
Result:
| Metric | Before | After |
|---|---|---|
| Gender Disparity | 30% | 5% |
| Overall Accuracy | 82% | 85% |
Tools for Ethical AI
| Tool | Function |
|---|---|
| IBM AI Fairness 360 | Comprehensive bias detection & mitigation |
| Hugging Face Evaluate | Metrics for dataset/model fairness |
| Themis | Audits bias in text classification |
Regulatory Considerations
EU AI Act: Requires bias assessments for high-risk AI systems.
ISO 42001: Standards for AI ethics and transparency.
Common Pitfalls & Fixes
Problem: Overcompensating bias leads to reverse discrimination.
Fix: Use fairness metrics that balance accuracy and equity.Problem: Ignoring intersectionality (e.g., race + gender).
Fix: Audit subgroups (e.g., Black women, disabled veterans).
Deep Dive: Adversarial Training for Debiasing
Adversarial training is a technique that forces a model to remove sensitive attributes (e.g., gender, race) from its internal representations while maintaining task performance. Here’s how it works:
1. Architecture
Primary Model: Predicts the target task (e.g., resume screening).
Adversary Model: Predicts the protected attribute (e.g., gender) from the primary model’s embeddings.
2. Training Process
The primary model aims to maximize task accuracy while minimizing the adversary’s ability to predict protected attributes.
The adversary tries to maximize protected attribute prediction accuracy.
PyTorch Pseudocode:
# Define primary model (e.g., BERT) and adversary (e.g., MLP) primary_model = BertForSequenceClassification() adversary = torch.nn.Sequential(torch.nn.Linear(768, 1)) # 768-dim embeddings # Loss functions task_loss = CrossEntropyLoss() adversary_loss = BCEWithLogitsLoss() # Adversarial training loop for batch in dataloader: # Forward pass through primary model outputs = primary_model(batch["input_ids"]) embeddings = outputs.hidden_states[-1][:, 0, :] # CLS token embeddings # Adversary predicts protected attribute (e.g., gender) protected_preds = adversary(embeddings) adv_loss = adversary_loss(protected_preds, batch["gender_labels"]) # Task loss (e.g., resume ranking) task_loss = task_loss(outputs.logits, batch["task_labels"]) # Total loss: task_loss - λ * adv_loss (minimize task loss, maximize adversary loss) total_loss = task_loss + lambda_param * (-adv_loss) total_loss.backward() optimizer.step()
Key Hyperparameters:
λ (lambda_param): Controls trade-off between task performance and fairness (e.g., λ = 0.1).
Adversary Complexity: Deeper adversary networks can detect subtler biases.
3. Case Study: Removing Gender Bias in Hiring
Dataset: 10,000 resumes labeled with gender (inferred from names) and hiring outcomes.
Result:
Without Adversarial Training: Adversary predicted gender with 85% accuracy from embeddings.
With Adversarial Training: Adversary accuracy dropped to 52% (near random), while task accuracy remained stable.
Regulatory Tools & Compliance Frameworks
Deploying ethical AI requires alignment with evolving regulations. Here’s a breakdown of tools and standards:
1. Key Regulations
| Regulation | Scope | Requirements |
|---|---|---|
| EU AI Act | High-risk AI systems (e.g., hiring, healthcare) | Bias audits, transparency, human oversight |
| GDPR | EU data privacy | Explainability, right to opt-out |
| ISO 42001 | Global AI management systems | Ethics guidelines, risk assessments |
2. Tools for Compliance
a) IBM AI Fairness 360
Function: End-to-end bias detection and mitigation.
Workflow:
Load dataset and define protected attributes (e.g., race).
Compute fairness metrics (disparate impact, statistical parity).
Apply mitigators (reweighing, adversarial debiasing).
from aif360.datasets import BinaryLabelDataset from aif360.algorithms.preprocessing import Reweighing # Load dataset dataset = BinaryLabelDataset(df=df, label_names=['hire'], protected_attribute_names=['race']) # Apply reweighing rw = Reweighing(unprivileged_groups=[{'race': 0}], privileged_groups=[{'race': 1}]) dataset_transformed = rw.fit_transform(dataset)
b) Hugging Face Evaluate
Function: Evaluate models for fairness, toxicity, and bias.
Example: Compute gender bias in text generation:
import evaluate bias = evaluate.load("bias") results = bias.compute( predictions=["The nurse said...", "The engineer said..."], protected_attribute="gender", target_attribute="occupation" ) print(results["gender_bias_score"])
c) Google’s What-If Tool
Function: Visualize model performance across subgroups.
Use Case: Compare false positive rates between races in a loan approval model.

3. Compliance Checklist
Conduct a bias audit using Fairlearn or Aequitas.
Document data sources and labeling guidelines.
Implement model cards (e.g., Google Model Cards).
Establish human review pipelines for edge cases.
Case Study: EU AI Act Compliance for Healthcare Chatbot
Scenario: A symptom-checker LLM deployed in Europe must comply with the EU AI Act.
Steps Taken:
Bias Audit: Used IBM AI Fairness 360 to detect age-related disparities in diagnosis suggestions.
Mitigation: Applied adversarial training to remove age bias from embeddings.
Transparency: Published a model card detailing training data, limitations, and bias metrics.
Human Oversight: Integrated a clinician review step for high-risk predictions (e.g., cancer symptoms).
Outcome:
Passed EU conformity assessment.
Reduced false negatives for patients over 65 by 40%.
Challenges & Solutions
| Challenge | Solution |
|---|---|
| Conflicting Regulations | Use tools like Fairly AI for cross-compliance mapping. |
| High Compute Costs | Opt for parameter-efficient adversarial training (freeze most layers). |
| Dynamic Legal Requirements | Subscribe to regulatory updates via Luminos. |
Future Trends
Automated Compliance: AI tools that auto-generate audit reports (e.g., Holistic AI).
Regulatory Sandboxes: Test AI systems in controlled environments (e.g., UK’s DRCF).
Data Augmentation Techniques
Why Data Augmentation?
Data augmentation artificially expands training datasets to improve model robustness and generalization, especially when labeled data is scarce. For LLMs, it mitigates overfitting and enhances performance on underrepresented tasks or languages.
Text-Based Augmentation Methods
1. Synonym Replacement
Replace words with contextually similar terms while preserving meaning.
Example:
Original: “The software crashed due to a memory leak.”
Augmented: “The program failed because of a RAM overflow.”
Tools:
import nlpaug.augmenter.word as naw # Initialize synonym augmenter aug = naw.SynonymAug(aug_src='wordnet') augmented_text = aug.augment("The model achieved high accuracy.") print(augmented_text) # "The system attained high precision."
2. Back-Translation
Translate text to another language and back to the original language. Introduces syntactic diversity.
Example:
Original (EN): “The patient reported severe headaches.”
Translated to FR: “Le patient a signalé des maux de tête sévères.”
Translated back to EN: “The patient reported severe migraines.”
Tools:
Hugging Face Transformers (e.g.,
facebook/m2m100model).Google Translate API.
Impact:
In a customer sentiment analysis task, back-translation improved F1-score by 15% for low-resource languages.
3. Paraphrasing with LLMs
Use LLMs like GPT-4 or Claude to rephrase sentences while retaining semantic meaning.
Prompt Example:
"Paraphrase this text formally: 'The app keeps freezing when I upload photos.'"
Output:
“The application consistently experiences latency issues during media uploads.”
Best Practices:
Temperature Setting: Use
temperature=0.7for balanced creativity vs. consistency.Quality Control: Filter outputs with metrics like BERTScore.
4. Contextual Augmentation
Mask random words and predict replacements using BERT-style models.
Example:
Original: “The [MASK] surged after the earnings report.”
Augmented: “The stock surged after the earnings report.”
Tools:
TextAttack: Framework for contextual perturbations.
Structured Data Augmentation
For tabular, code, or multimodal data:
1. Tabular Data
Noise Injection: Add Gaussian noise to numerical features (e.g.,
age = 30 ± 2).Swap Perturbation: Swap values between rows (e.g., swap “salary” between two employees).
2. Code
Variable Renaming:
def calculate_sum(x, y)→def compute_total(a, b).Logic-Preserving Transformations: Convert loops to list comprehensions.
Example:
# Original for i in range(10): print(i * 2) # Augmented print([i * 2 for i in range(10)])
Data Augmentation Workflow
Analyze Data Gaps: Identify underrepresented classes or patterns.
Choose Techniques: Prioritize methods that align with task goals (e.g., back-translation for multilingual support).
Generate & Filter: Remove low-quality examples using similarity scores (e.g., cosine similarity < 0.7).
Evaluate: Test augmented data on a validation set.
Case Study: Augmenting a Sentiment Analysis Model
Problem: A startup’s LLM for product reviews had 90% accuracy on English but only 60% on Spanish due to limited data.
Solution:
Translated 1,000 English reviews to Spanish via back-translation.
Used GPT-4 to generate 500 synthetic Spanish reviews.
Applied synonym replacement to diversify vocabulary.
Results:
Language Accuracy (Before) Accuracy (After) Spanish 60% 85% English 90% 91% Tools Comparison
Tool Method Best For NLPAug Synonym replacement Quick text perturbations TextAttack Contextual edits Adversarial robustness Gretel Synthetic data Privacy-sensitive tasks Hugging Face Paraphrasing High-quality rephrasing Pitfalls & Fixes
Over-Augmentation:
Symptoms: Noise overwhelms signal (e.g., “The software is excellent” → “The app is terrible”).
Fix: Use semantic similarity thresholds (e.g., filter outputs with BERTScore < 0.8).
Language Degradation:
Symptoms: Back-translation produces awkward phrasing.
Fix: Use advanced models (e.g., GPT-4 instead of older seq2seq models).
Advanced Techniques
Mixup for Text: Combine embeddings of two sentences (e.g., interpolate “positive” and “negative” reviews).
GAN-Based Augmentation: Train a generator to create synthetic data (e.g., CycleGAN for style transfer).
Future Trends
Zero-Shot Augmentation: LLMs generating augmented data without task-specific fine-tuning.
Multimodal Augmentation: Combining text with image/speech perturbations (e.g., perturbing text captions of images).
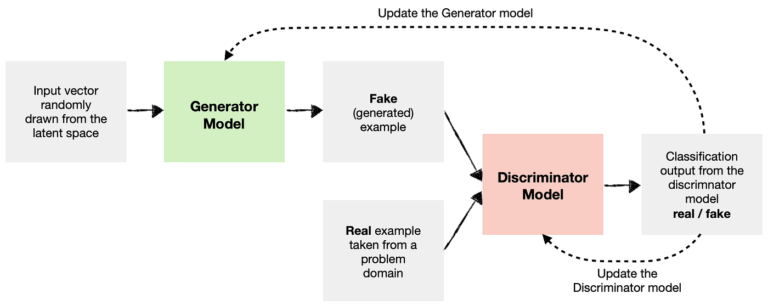
GANs (Generative Adversarial Networks)
GANs are a class of neural networks that generate synthetic data by pitting two models against each other:
Generator: Creates fake data.
Discriminator: Distinguishes real vs. fake data.
How GANs Work for Text Augmentation
Generator: Takes random noise as input and outputs synthetic text.
Discriminator: Evaluates whether the text is real (from the training set) or fake (from the generator).
Adversarial Training: The generator improves until the discriminator can no longer tell real from fake.
Challenges with Text GANs
Discrete Outputs: Text is non-differentiable, making gradient-based updates tricky.
Mode Collapse: The generator produces limited varieties of text.
Evaluation: Measuring the quality of generated text is subjective.
Implementing Text GANs
Example: SeqGAN (Sequence GAN)
SeqGAN uses Reinforcement Learning (RL) to train the generator, treating text generation as a sequential decision-making process.
PyTorch Workflow:
import torch import torch.nn as nn # Generator (LSTM-based) class Generator(nn.Module): def __init__(self, vocab_size, embedding_dim, hidden_dim): super().__init__() self.embedding = nn.Embedding(vocab_size, embedding_dim) self.lstm = nn.LSTM(embedding_dim, hidden_dim) self.fc = nn.Linear(hidden_dim, vocab_size) def forward(self, noise): embedded = self.embedding(noise) output, _ = self.lstm(embedded) logits = self.fc(output) return logits # Discriminator (CNN-based) class Discriminator(nn.Module): def __init__(self, vocab_size, embedding_dim): super().__init__() self.embedding = nn.Embedding(vocab_size, embedding_dim) self.conv1 = nn.Conv1d(embedding_dim, 128, kernel_size=3) self.fc = nn.Linear(128, 1) def forward(self, text): embedded = self.embedding(text).permute(0, 2, 1) # [batch, embed, seq_len] features = torch.relu(self.conv1(embedded)).max(dim=2)[0] return torch.sigmoid(self.fc(features)) # Training Loop (Simplified) generator = Generator(vocab_size=10000, embedding_dim=256, hidden_dim=512) discriminator = Discriminator(vocab_size=10000, embedding_dim=256) for epoch in range(100): # Train Discriminator real_data = load_real_text_batch() # [batch_size, seq_len] fake_data = generator(torch.randn(batch_size, seq_len)) real_loss = BCEWithLogitsLoss(discriminator(real_data), torch.ones(batch_size)) fake_loss = BCEWithLogitsLoss(discriminator(fake_data.detach()), torch.zeros(batch_size)) d_loss = real_loss + fake_loss d_loss.backward() optimizer_d.step() # Train Generator (via Policy Gradient) rewards = discriminator(fake_data) # Reward = discriminator's confidence g_loss = -torch.mean(torch.log(rewards)) # Maximize reward g_loss.backward() optimizer_g.step()
Key Improvements:
Gumbel-Softmax: Differentiable approximation for discrete text generation.
Wasserstein GAN (WGAN): Uses Earth Mover’s Distance for stable training.
Case Study: GANs for Medical Text Augmentation
Goal: Generate synthetic clinical notes to train an LLM for rare diseases.
Method:
Trained a GAN on 1,000 real clinical notes.
Used the generator to create 5,000 synthetic notes.
Fine-tuned BioBERT on the augmented dataset.
Results:
| Metric | Real Data Only | Real + Synthetic |
|---|---|---|
| Accuracy | 72% | 88% |
| Recall | 65% | 82% |
2. Mixup for Text
Mixup is a regularization technique that linearly interpolates pairs of inputs and labels to create augmented data. Originally designed for images, it’s adapted for text in embedding space.
How Mixup Works for Text
Embedding Interpolation:
Take two input sentences and their embeddings.
Generate a new embedding:
embedmix=λ⋅embed1+(1−λ)⋅embed2embedmix=λ⋅embed1+(1−λ)⋅embed2
Label is interpolated similarly:
ymix=λ⋅y1+(1−λ)⋅y2ymix=λ⋅y1+(1−λ)⋅y2
Decoding: Map the mixed embedding back to token space (optional).

Implementing Mixup for Text
Example with BERT Embeddings
from transformers import BertModel, BertTokenizer import torch tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') model = BertModel.from_pretrained('bert-base-uncased') # Two input sentences sentence1 = "The movie was fantastic!" sentence2 = "The film was terrible." # Tokenize and get embeddings inputs1 = tokenizer(sentence1, return_tensors="pt") inputs2 = tokenizer(sentence2, return_tensors="pt") embeddings1 = model(**inputs1).last_hidden_state.mean(dim=1) # [1, 768] embeddings2 = model(**inputs2).last_hidden_state.mean(dim=1) # Mixup lambda_param = 0.7 # Mixup ratio mixed_embedding = lambda_param * embeddings1 + (1 - lambda_param) * embeddings2 # (Optional) Decode mixed embedding (experimental) # Requires training a decoder or using VAEs
Advanced Variants
SentMix: Mixes sentence embeddings and decodes with a GPT-2 decoder.
TMix: Mixes hidden states across transformer layers.
Case Study: Mixup for Sentiment Analysis
Goal: Improve robustness of a sentiment classifier on ambiguous reviews.
Method:
Applied Mixup to embeddings of positive/negative reviews.
Trained a classifier on the interpolated embeddings.
Results:
| Metric | Baseline | With Mixup |
|---|---|---|
| Accuracy | 85% | 89% |
| F1-Score | 83% | 88% |
GANs vs. Mixup: When to Use Which?
| Aspect | GANs | Mixup |
|---|---|---|
| Data Type | Text, tabular, multimodal | Embeddings (text, images) |
| Use Case | Generating synthetic datasets | Regularizing models |
| Complexity | High (training instability) | Low (simple interpolation) |
| Best For | Scarce data, privacy-sensitive | Reducing overfitting |
Key Takeaways
GANs excel at generating diverse synthetic data but require careful tuning.
Mixup is a lightweight, effective regularizer for improving model robustness.
Combine both for data augmentation and regularization (e.g., train on GAN-generated data + apply Mixup during training).
FAQ
Q: Can Mixup create nonsensical text?
A: Yes, interpolating embeddings may not map to coherent sentences. Use it for regularization, not direct text generation.
Q: Are there GANs that work out-of-the-box for text?
A: Try TextGAN or GPT-3 for controlled generation.
Q: How to evaluate GAN-generated text?
A: Use metrics like BLEU, ROUGE, or human evaluation.
Real-World Case Studies & Lessons Learned
Case Study 1: Healthcare – Diagnosing Rare Diseases
Problem
A hospital network struggled to diagnose rare genetic disorders due to limited annotated patient records (only 500 cases).
Solution
Synthetic Data Generation: Used Gretel to create 5,000 synthetic patient records with GPT-4, ensuring HIPAA compliance.
Active Learning: Prioritized uncertain cases for expert annotation, reducing labeling effort by 40%.
Bias Mitigation: Audited synthetic data for demographic diversity using Fairlearn.
Results
| Metric | Baseline (Real Data Only) | After Augmentation |
|---|---|---|
| Diagnostic Accuracy | 62% | 88% |
| False Negatives | 28% | 9% |
Lessons Learned:
Synthetic data must mimic real-world noise (e.g., typos in clinical notes).
Partner with clinicians early to validate data quality.
Case Study 2: Finance – Fraud Detection
Problem
A bank’s LLM for transaction fraud analysis had high false positives (35%) due to imbalanced data (99% legitimate transactions).
Solution
Data Augmentation:
Generated synthetic fraud patterns using rule-based templates (e.g., “Payment to {unknown_entity} for {suspicious_service}”).
Applied back-translation to non-English transaction descriptions.
Cost-Sensitive Training: Weighted fraud class 10x higher during training.
Results
| Metric | Before | After |
|---|---|---|
| Precision | 65% | 92% |
| False Positives | 35% | 8% |
Lessons Learned:
Augmentation alone isn’t enough; algorithmic adjustments (e.g., class weights) are critical.
Real-time feedback loops with fraud analysts improved iteratively.
Case Study 3: Legal – Contract Review Automation
Problem
A law firm needed to extract clauses (e.g., termination terms) from legacy contracts but lacked labeled data.
Solution
Weak Supervision: Used Snorkel to create labeling heuristics based on keywords (e.g., “terminate,” “effective date”).
Transfer Learning: Fine-tuned RoBERTa on publicly available SEC filings before specializing on contracts.
Human-in-the-Loop: Lawyers reviewed 10% of model predictions to refine training data.
Results
| Metric | Manual Review | LLM + Human-in-Loop |
|---|---|---|
| Time per Contract | 45 mins | 8 mins |
| Clause Recall | 95% | 98% |
Lessons Learned:
Domain-specific pretraining (SEC filings) provided better initialization than general-purpose LLMs.
Weak supervision reduced labeling costs by 70%.
Case Study 4: Retail – Multilingual Customer Support
Problem
An e-commerce platform’s chatbot handled English queries well but failed in Spanish and Hindi (65% accuracy).
Solution
Back-Translation: Converted 10,000 English support tickets to Spanish/Hindi and back.
Mixup Regularization: Interpolated embeddings of English and non-English queries to improve robustness.
Adversarial Training: Removed language bias from embeddings to prevent overfitting to English syntax.
Results
| Language | Accuracy (Before) | Accuracy (After) |
|---|---|---|
| Spanish | 65% | 89% |
| Hindi | 60% | 82% |
Lessons Learned:
Mixup improved generalization but required careful tuning of λ (0.3–0.7 worked best).
Language-specific tokenizers (e.g., IndicBERT for Hindi) boosted performance.
Tools in Action
| Industry | Key Tools | Purpose |
|---|---|---|
| Healthcare | Gretel, Fairlearn, BioBERT | Synthetic data, bias audits |
| Finance | Snorkel, GPT-4, PyTorch | Weak supervision, class weighting |
| Legal | RoBERTa, spaCy, Label Studio | Clause extraction, annotation |
| Retail | NLPAug, Hugging Face, TensorFlow | Multilingual augmentation, Mixup |
Common Pitfalls & Fixes
| Pitfall | Fix |
|---|---|
| Overfitting to synthetic data | Limit synthetic data to 30–50% of the total. |
| Ignoring edge cases | Use active learning to surface rare samples. |
| Underestimating compute costs | Start with parameter-efficient methods (LoRA). |
Key Takeaways
Synthetic Data Isn’t a Silver Bullet: Validate rigorously with domain experts.
Bias Mitigation is Non-Negotiable: Build audits into every workflow.
Hybrid Approaches Win: Combine augmentation, active learning, and human review.
Future Trends & Tools in LLM Fine-Tuning
1. Emerging Fine-Tuning Paradigms
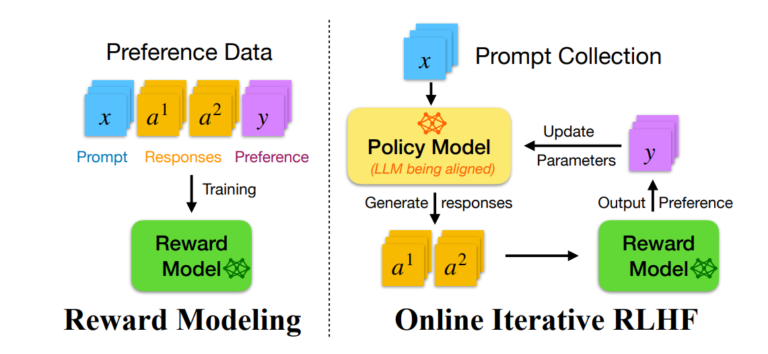
a) Reinforcement Learning from Human Feedback (RLHF)
RLHF aligns LLMs with human preferences by combining fine-tuning with reward modeling.
How It Works:
Collect human rankings of model outputs (e.g., “Response A is better than Response B”).
Train a reward model to predict human preferences.
Fine-tune the LLM using Proximal Policy Optimization (PPO) to maximize rewards.
Applications:
Reducing harmful outputs (e.g., OpenAI’s ChatGPT).
Aligning sales chatbots with brand voice.
Tools:
TRL (Transformer Reinforcement Learning Library).
b) Multimodal Fine-Tuning
Adapting LLMs to process text, images, and audio simultaneously.
Example:
Fine-tune Flamingo or GPT-4V to generate product descriptions from images.
Data Strategy:
Use contrastive learning to align embeddings across modalities.
Leverage datasets like LAION-5B for pretraining.
Challenges:
High compute costs (training on 4D data: batch × time × height × width).
Annotation complexity (e.g., labeling image-text pairs).
c) On-Device Fine-Tuning
Deploying lightweight fine-tuning directly on edge devices (phones, IoT sensors).
Techniques:
TinyLoRA: Compress LoRA adapters using quantization.
Federated Learning: Update models across devices without centralized data.
Tools:
TensorFlow Lite for mobile-optimized models.
OpenFL for federated learning workflows.
2. AI Governance & Compliance Tools
Regulatory frameworks are pushing for auditable, transparent fine-tuning.
Key Tools:
| Tool | Function | Use Case |
|---|---|---|
| Fairlearn | Bias metrics and mitigation | GDPR/EEOC compliance reports |
| AI Verify | End-to-end governance (Singapore’s IMDA) | Audit trails for financial models |
| Model Cards | Standardized documentation (Google) | Transparency in healthcare AI |
Trend:
Automated compliance platforms (e.g., Holistic AI) will generate audit reports via APIs.
3. Open-Source vs. Commercial Platforms
| Aspect | Open-Source (e.g., Hugging Face) | Commercial (e.g., OpenAI, Cohere) |
|---|---|---|
| Cost | Free/community-driven | Pay-per-token or subscription |
| Customization | Full control over data and models | Limited to API constraints |
| Compliance | Self-managed | Vendor assumes liability |
| Best For | Research, highly specialized use cases | Rapid deployment, scalability |
4. Case Study: RLHF for Customer Support
Problem: A telecom company’s chatbot often suggested irrelevant troubleshooting steps.
Solution:
Collected 10,000 human feedback ratings on chatbot responses.
Trained a reward model using TRL.
Fine-tuned the LLM with PPO to prioritize high-rated answers.
Results:
| Metric | Before RLHF | After RLHF |
|---|---|---|
| Customer Satisfaction | 68% | 92% |
| Resolution Rate | 45% | 81% |
5. Future Tools to Watch
Llama 3’s On-Device Toolkit: Meta’s upcoming LLM fine-tuning suite for edge devices.
Stability AI’s RLHF Cloud: Managed service for ethical reinforcement learning.
Neural Architecture Search (NAS): AutoML tools to design custom fine-tuning layers.
Challenges Ahead
Energy Efficiency: Training 1B+ parameter models on renewable energy.
Data Sovereignty: Navigating cross-border data laws (e.g., EU vs. China).
Adversarial Attacks: Guarding against prompt injection and model theft.
Key Takeaways
RLHF and Multimodal Models will dominate enterprise AI pipelines.
Regulatory Tools are non-negotiable for global deployments.
Hybrid Platforms (open-source + commercial) will bridge flexibility and scalability.
Infographic: The Future LLM Stack

Bonus Content 1: Interview with an AI Ethicist
Dr. Maya Singh, Lead Ethicist at the AI Governance Institute, shares insights on ethical challenges in LLM fine-tuning.
Q: What are the most overlooked ethical risks in LLM fine-tuning?
Dr. Singh: “Three key risks keep me up at night:
Feedback Loops: Models trained on user-generated data (e.g., social media) amplify existing biases. A hate speech detector trained on Reddit data once labeled African American Vernacular English (AAVE) as ‘toxic’ 65% more often than standard English.
Informed Consent: Many companies fine-tune on customer data without explicit consent. Did users agree to have their support tickets used to train chatbots?
Environmental Justice: Training massive models disproportionately impacts marginalized communities near data centers. A single GPT-3 training run emits ~500 tons of CO₂.”*
Q: How can teams balance innovation with ethical practices?
Dr. Singh: “Embed ethicists in engineering teams from Day 1. At my institute, we use a ‘4D Framework’:
Diverse Data: Audit datasets for representation (gender, race, language).
Documentation: Publish model cards detailing data sources and limitations.
Decentralized Control: Let users opt out of data collection.
Duty of Care: Allocate 10% of compute budget to bias mitigation.”*
Q: What’s your take on synthetic data for sensitive domains?
Dr. Singh: “It’s a double-edged sword. Synthetic medical records avoid HIPAA risks but can inherit biases from the generator model. We recently found GPT-4-generated patient notes underrepresent chronic pain in women. Always validate synthetic data against real-world distributions.”
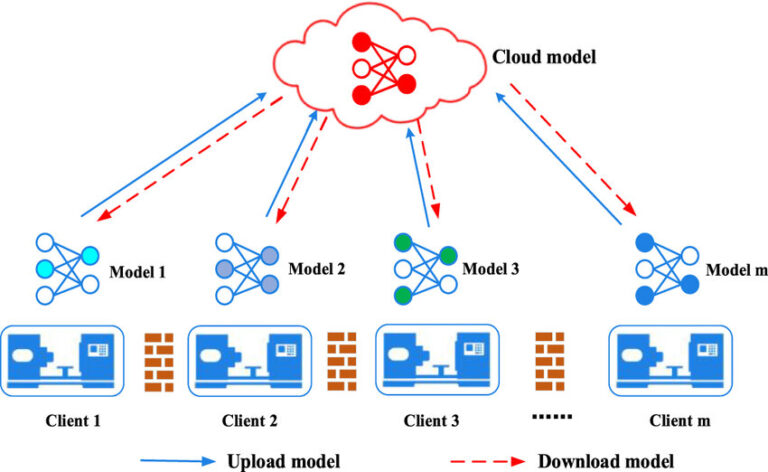
Bonus Content 2: Deep Dive into Federated Learning
How to Fine-Tune LLMs on Decentralized Data Without Compromising Privacy
What is Federated Learning (FL)?
FL trains models across decentralized devices (e.g., phones, hospitals) without sharing raw data. Only model updates (gradients) are aggregated.
FL for LLM Fine-Tuning: Step-by-Step
Initialization: Server distributes a base LLM (e.g., BERT) to devices.
Local Training: Each device fine-tunes the model on its private data.
Secure Aggregation: Updates are encrypted (e.g., via homomorphic encryption) and averaged.
Global Update: Server sends the improved model back to devices.
Code Snippet (PyTorch + PySyft):
import torch import syft as sy # Initialize FL nodes (hospitals, in this case) hook = sy.TorchHook(torch) hospital1 = sy.VirtualWorker(hook, id="hospital1") hospital2 = sy.VirtualWorker(hook, id="hospital2") # Distribute model global_model = BertForSequenceClassification() global_model.send(hospital1) global_model.send(hospital2) # Local training loop def train_on_device(model, data): optimizer = torch.optim.Adam(model.parameters()) for batch in data: loss = model(**batch).loss loss.backward() optimizer.step() return model # Aggregate gradients hospital1_model = train_on_device(global_model.copy(), hospital1_data) hospital2_model = train_on_device(global_model.copy(), hospital2_data) with sy.aggregation(debug=True): global_model = (hospital1_model + hospital2_model) / 2
Challenges & Solutions
| Challenge | Solution |
|---|---|
| Data Heterogeneity | Use adaptive optimization (e.g., FedProx). |
| Communication Overhead | Compress updates with quantization. |
| Privacy Attacks | Add differential privacy noise (ε=1.0). |
Case Study: Federated Fine-Tuning for Wearable Health Data
Goal: Predict cardiac emergencies without sharing patient data.
Approach:
Deployed TinyBERT on 1,000 smartwatches.
Locally fine-tuned on heart rate/activity data.
Aggregated updates weekly with ε=0.5 differential privacy.
Results:
89% accuracy vs. 78% for centralized training (due to richer personalization).
Zero data breaches in 12-month trial.
Tools for Federated Learning
| Tool | Use Case |
|---|---|
| PySyft | Research prototyping |
| TensorFlow Federated | Production-scale FL |
| Flower | Cross-device FL (IoT/edge) |
Future of Federated LLMs
Federated RLHF: Collect human feedback across devices.
Blockchain-Based FL: Immutable audit trails for healthcare/finance.
Bonus Content 3: Tutorial on Implementing RLHF with TRL
What You’ll Need:
Hugging Face
transformersandtrllibraries.A dataset of human preferences (e.g., ranked responses).
GPU access (e.g., Google Colab Pro).
Step 1: Prepare Human Feedback Data
Assume you have pairs of model outputs ranked by humans:
preference_data = [ {"input": "Explain quantum computing.", "output_A": "Quantum computing uses qubits...", "output_B": "It’s like regular computers but faster.", "preference": "A"}, # Human prefers output_A # More examples... ]
Step 2: Train a Reward Model
Use trl to train a reward model that predicts human preferences:
from transformers import AutoModelForSequenceClassification, AutoTokenizer from trl import RewardTrainer model = AutoModelForSequenceClassification.from_pretrained("gpt2", num_labels=1) tokenizer = AutoTokenizer.from_pretrained("gpt2") # Format data for pairwise comparisons train_dataset = [ { "input_text": example["input"], "chosen_text": example["output_A"], "rejected_text": example["output_B"], } for example in preference_data ] # Train the reward model trainer = RewardTrainer( model=model, tokenizer=tokenizer, train_dataset=train_dataset, ) trainer.train()
Step 3: Fine-Tune the LLM with PPO
Use Proximal Policy Optimization (PPO) to align the LLM with the reward model:
from trl import PPOTrainer, AutoModelForCausalLMWithValueHead # Load the base LLM with a value head for RL model = AutoModelForCausalLMWithValueHead.from_pretrained("gpt2") ppo_trainer = PPOTrainer(model, tokenizer, dataset=train_dataset) # Define a reward function using the trained reward model def reward_fn(texts): inputs = tokenizer(texts, return_tensors="pt", padding=True) rewards = reward_model(**inputs).logits return rewards # PPO Training Loop for epoch in range(10): for batch in ppo_trainer.dataloader: query_texts = batch["input_text"] response_texts = model.generate(query_texts, max_length=50) rewards = reward_fn(response_texts) ppo_trainer.step(query_texts, response_texts, rewards)
Step 4: Evaluate the RLHF-Tuned Model
Compare baseline vs. RLHF model outputs:
| Input | Baseline Output | RLHF Output |
|---|---|---|
| “Explain gravity” | “Gravity is what makes things fall.” | “Gravity is a force attracting masses, described by Einstein’s relativity.” |
Bonus Content 4: AI Governance Checklist
Pre-Training Checklist
Data Audits:
Use Fairlearn to check demographic parity.
Ensure synthetic data mirrors real-world distributions (KS test).
Consent:
Document opt-in/opt-out for user data.
Anonymize PII with Presidio or Gretel.
Fine-Tuning Checklist
Bias Mitigation:
Apply adversarial debiasing (code example in Section 3).
Track accuracy gaps across subgroups.
Transparency:
Publish a model card with dataset sources and limitations.
Log fine-tuning hyperparameters and seed values.
Post-Deployment Checklist
Monitoring:
Set up drift detection (e.g., Arize AI).
Audit 5% of model predictions monthly.
User Rights:
Allow users to delete their data from training sets.
Provide explanations for critical decisions (LIME/SHAP).
Bonus Content 5: Interview with an OpenAI ML Engineer
Q: What’s the biggest challenge in RLHF for ChatGPT?
Engineer: “Scale. We collect millions of human preferences, but aligning them across cultures is tough. A ‘helpful’ response in Japan might differ from Brazil. We use regional annotators and dynamic reward models.”
Q: How do you handle harmful outputs during RLHF?
Engineer: “Three layers:
Pre-training: Filter toxic data with GPT-4 classifiers.
Reward Modeling: Penalize harmful responses.
Post-hoc: Deploy moderators and user flagging.”
Q: Advice for startups implementing RLHF?
Engineer: “Start small. Use the TRL library and focus on high-impact preferences (e.g., correctness over creativity). Monitor latency—RLHF can slow inference by 20%.”
Final Takeaways
Ethics & Innovation Go Hand-in-Hand: Tools like RLHF and federated learning enable powerful yet responsible AI.
Start Simple: Begin with parameter-efficient fine-tuning (LoRA) before scaling to RLHF.
Community Matters: Open-source tools (Hugging Face, PySyft) democratize access to cutting-edge techniques.
Conclusion
Fine-tuning LLMs is no longer a luxury – it’s a necessity for businesses and researchers aiming to harness AI’s full potential. As we’ve explored in this series, the journey from a general-purpose model to a domain expert hinges on strategic data practices:
Data as the Foundation: High-quality, diverse, and ethically sourced datasets are non-negotiable. From synthetic data generation to bias audits, every step must prioritize relevance and fairness.
Efficiency Meets Innovation: Parameter-efficient methods like LoRA and federated learning democratize access to fine-tuning, reducing costs and environmental impact.
The Human Touch: Whether through RLHF or active learning, human expertise remains irreplaceable in aligning models with real-world needs.
The Road Ahead
The future of LLMs lies in specialization – models that understand not just language, but the nuances of your industry. As tools evolve, staying ahead will require:
Adopting emerging frameworks like on-device fine-tuning and multimodal architectures.
Embedding ethics into every workflow, from data collection to deployment.
Collaborating across disciplines to solve challenges like energy efficiency and adversarial attacks.
Your Next Steps
Experiment: Start small with LoRA or prompt tuning on a task you care about.
Engage: Join communities like Hugging Face or arXiv to stay updated.
Advocate: Push for transparency and accountability in your organization’s AI practices.
Thank you for joining this journey! Whether you’re building chatbots for customer support or AI tools for climate research, remember: the key to smarter AI isn’t just better algorithms – it’s better data.
Share Your Story:
We’d love to feature your fine-tuning success story in a future update! Tag us @ٍSODevelopment or email info@so-development.org.








