Introduction
What is Reinforcement Learning (RL)?
Reinforcement Learning (RL) is a type of machine learning where an agent learns to make decisions by performing actions in an environment to maximize some notion of cumulative reward. Unlike supervised learning, where the model is trained on a labeled dataset, RL relies on the concept of trial and error. The agent interacts with the environment, receives feedback in the form of rewards or penalties, and adjusts its actions accordingly to achieve the best possible outcome.
The Role of Human Feedback in AI
Human feedback has become increasingly important in the development of AI systems, particularly in areas where the desired behavior is complex or difficult to define algorithmically. By incorporating human feedback, AI systems can learn to align more closely with human values, preferences, and ethical considerations. This is especially crucial in applications like natural language processing, robotics, and recommender systems, where the stakes are high, and the impact on human lives is significant.
Overview of Reinforcement Learning from Human Feedback (RLHF)
Reinforcement Learning from Human Feedback (RLHF) is an approach that combines traditional RL techniques with human feedback to guide the learning process. Instead of relying solely on predefined reward functions, RLHF uses human feedback to shape the reward signal, allowing the agent to learn behaviors that are more aligned with human intentions. This approach has been particularly effective in fine-tuning large language models, improving the safety and reliability of AI systems, and enabling more natural human-AI interactions.
Importance of RLHF in Modern AI
As AI systems become more integrated into our daily lives, the need for models that can understand and align with human values becomes paramount. RLHF offers a promising pathway to achieving this alignment by leveraging human feedback to guide the learning process. This not only improves the performance of AI systems but also addresses critical ethical concerns, such as bias, fairness, and transparency. By incorporating human feedback, RLHF helps ensure that AI systems are not only intelligent but also responsible and trustworthy.
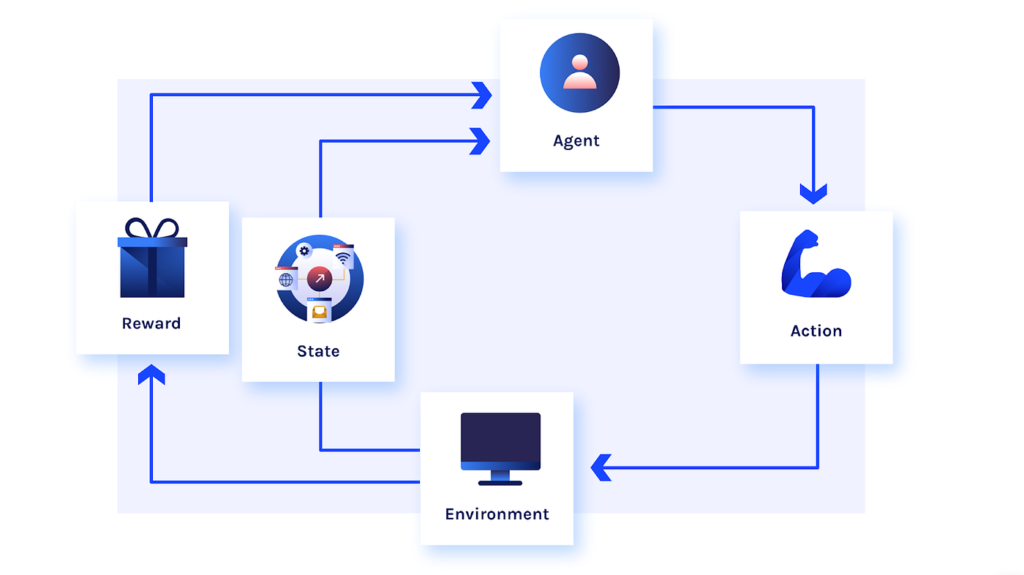
Foundations of Reinforcement Learning
Key Concepts in Reinforcement Learning
Agent, Environment, and Actions
In RL, the agent is the entity that learns and makes decisions. The environment is the world in which the agent operates, and it can be anything from a virtual game to a physical robot navigating a room. The agent takes actions in the environment, which lead to changes in the environment’s state. The agent’s goal is to learn a policy—a strategy that dictates which actions to take in each state to maximize cumulative rewards.
Rewards and Policies
A reward is a scalar feedback signal that the agent receives after taking an action in a given state. The agent’s objective is to maximize the cumulative reward over time. A policy is a mapping from states to actions, and it defines the agent’s behavior. The policy can be deterministic (always taking the same action in a given state) or stochastic (taking actions with a certain probability).
Value Functions and Q-Learning
The value function estimates the expected cumulative reward that the agent can achieve from a given state, following a particular policy. The Q-value function (or action-value function) estimates the expected cumulative reward for taking a specific action in a given state and then following the policy. Q-Learning is a popular RL algorithm that learns the Q-value function through iterative updates, allowing the agent to make optimal decisions.
Exploration vs. Exploitation
One of the fundamental challenges in RL is the trade-off between exploration and exploitation. Exploration involves trying out new actions to discover their effects, while exploitation involves choosing actions that are known to yield high rewards. Striking the right balance between exploration and exploitation is crucial for effective learning, as too much exploration can lead to inefficiency, while too much exploitation can result in suboptimal behavior.
Markov Decision Processes (MDPs)
A Markov Decision Process (MDP) is a mathematical framework used to model decision-making problems in RL. An MDP is defined by a set of states, a set of actions, a transition function that describes the probability of moving from one state to another, and a reward function that specifies the reward for each state-action pair. The Markov property states that the future state depends only on the current state and action, not on the sequence of events that preceded it.
Deep Reinforcement Learning (DRL)
Neural Networks in RL
Deep Reinforcement Learning (DRL) combines RL with deep learning, using neural networks to approximate value functions or policies. This allows RL algorithms to scale to high-dimensional state and action spaces, such as those encountered in complex environments like video games or robotic control tasks.
Deep Q-Networks (DQN)
Deep Q-Networks (DQN) are a type of DRL algorithm that uses a neural network to approximate the Q-value function. DQN has been successfully applied to a wide range of tasks, including playing Atari games at a superhuman level. The key innovation in DQN is the use of experience replay, where the agent stores past experiences and samples them randomly to update the Q-network, improving stability and convergence.
Policy Gradient Methods
Policy Gradient Methods are another class of DRL algorithms that directly optimize the policy by adjusting its parameters to maximize expected rewards. Unlike value-based methods like DQN, which learn a value function and derive the policy from it, policy gradient methods learn the policy directly. This approach is particularly useful in continuous action spaces, where the number of possible actions is infinite.
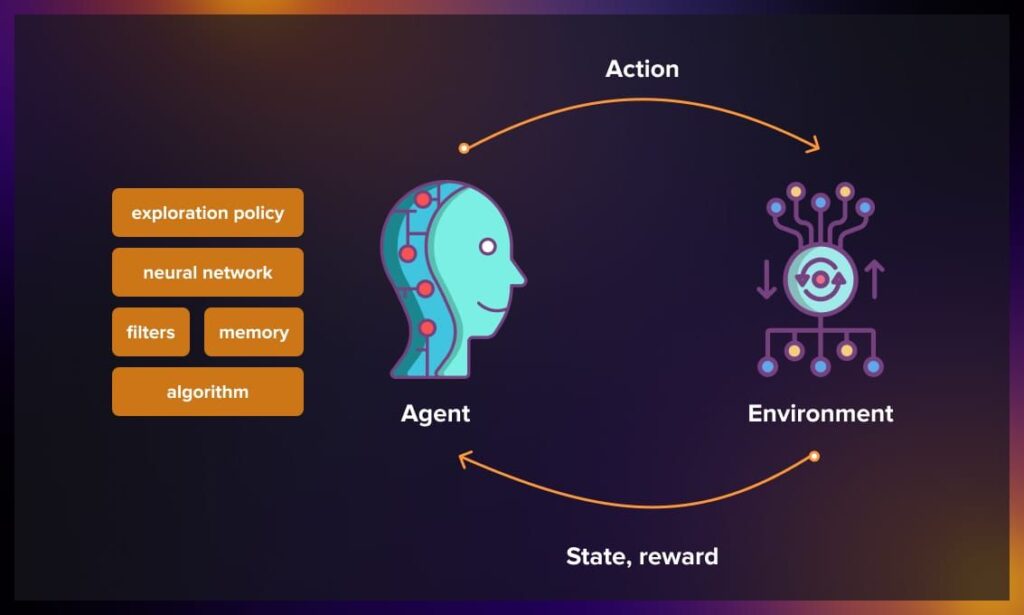
Human Feedback in Machine Learning
The Need for Human Feedback
In many real-world applications, the desired behavior of an AI system is difficult to define explicitly using a reward function. For example, in natural language processing, the “correct” response to a user’s query may depend on context, tone, and cultural nuances that are hard to capture algorithmically. Human feedback provides a way to guide the learning process by incorporating human judgment, preferences, and values into the training of AI models.
Types of Human Feedback
Explicit Feedback
Explicit feedback involves direct input from humans, such as ratings, labels, or corrections. For example, in a recommender system, users might rate movies on a scale of 1 to 5, providing explicit feedback on their preferences. Explicit feedback is straightforward to interpret but can be limited in scope and may not capture the full complexity of human preferences.
Implicit Feedback
Implicit feedback is inferred from user behavior rather than explicitly provided. For example, in a music streaming service, the system might infer user preferences based on which songs they listen to, skip, or replay. Implicit feedback is often more abundant than explicit feedback but can be noisy and harder to interpret.
Comparative Feedback
Comparative feedback involves humans comparing different outputs or actions and indicating which one they prefer. For example, in a dialogue system, users might be presented with two possible responses and asked to choose the one they find more appropriate. Comparative feedback is particularly useful in RLHF, as it provides a clear signal for optimizing the agent’s behavior.
Challenges in Incorporating Human Feedback
Subjectivity and Bias
Human feedback is inherently subjective and can be influenced by individual biases, cultural differences, and personal preferences. This can lead to challenges in ensuring that the feedback is representative and unbiased, particularly when the feedback is used to train models that will be deployed in diverse contexts.
Scalability
Collecting and processing human feedback at scale can be challenging, particularly in applications where feedback needs to be gathered continuously and in real-time. Ensuring the quality and consistency of feedback across a large and diverse user base is a significant challenge.
Feedback Sparsity
In many applications, human feedback is sparse, meaning that only a small fraction of the agent’s actions receive feedback. This can make it difficult for the agent to learn effectively, particularly in complex environments where the feedback is critical for guiding the learning process.
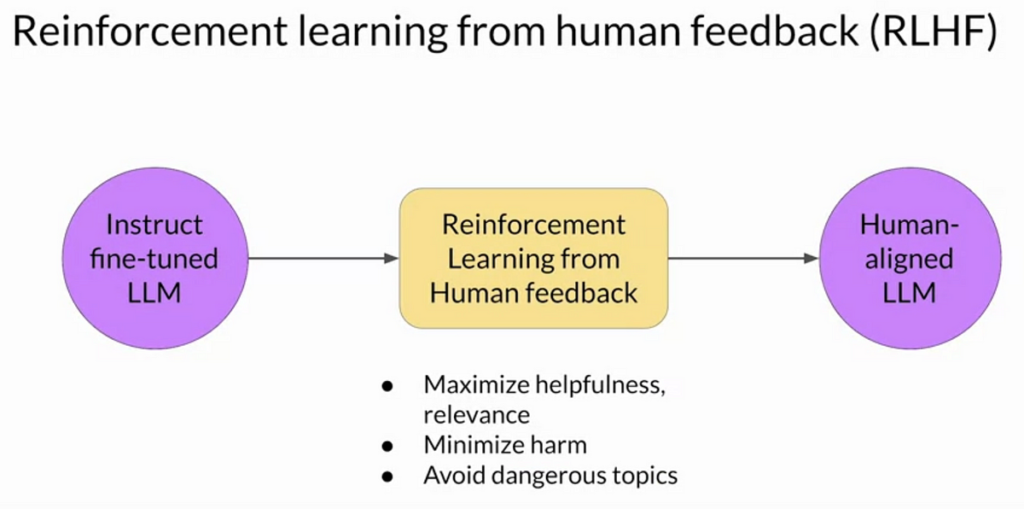
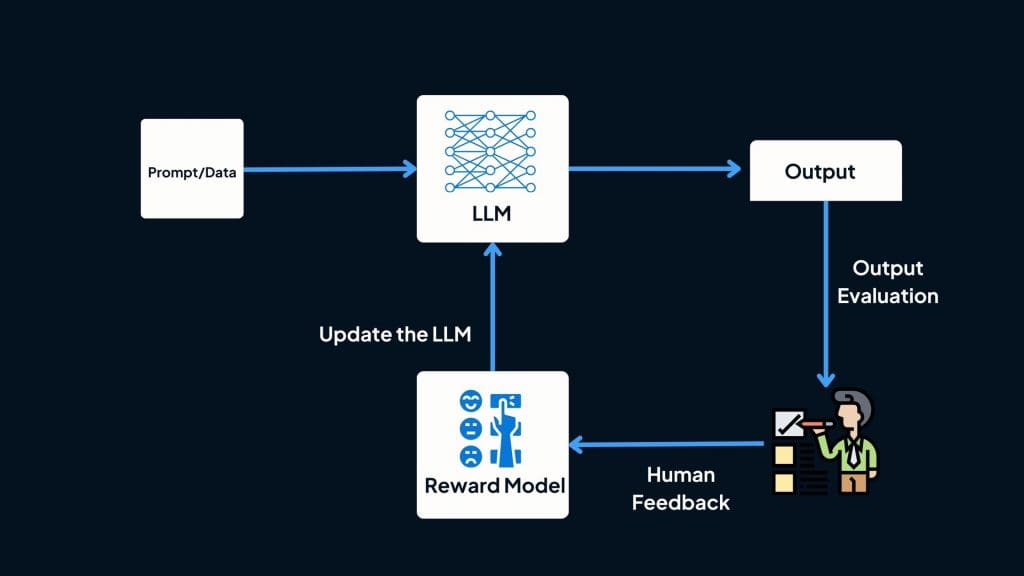
Reinforcement Learning from Human Feedback (RLHF)
Definition and Core Concepts
Reinforcement Learning from Human Feedback (RLHF) is an approach that integrates human feedback into the RL process to guide the agent’s learning. Instead of relying solely on predefined reward functions, RLHF uses human feedback to shape the reward signal, allowing the agent to learn behaviors that are more aligned with human intentions. This approach is particularly useful in applications where the desired behavior is complex, subjective, or difficult to define algorithmically.
The RLHF Framework
Data Collection: Gathering Human Feedback
The first step in RLHF is to collect human feedback that will be used to guide the agent’s learning. This feedback can take various forms, including explicit ratings, implicit behavior signals, or comparative judgments. The key challenge is to design feedback mechanisms that are both effective and scalable, ensuring that the feedback is representative and unbiased.
Reward Modeling: Translating Feedback into Rewards
Once human feedback is collected, the next step is to model the reward function based on this feedback. This involves translating the feedback into a reward signal that the agent can use to optimize its behavior. The reward model must be designed carefully to ensure that it accurately reflects human preferences and values, while also being computationally efficient.
Policy Optimization: Training the Agent
With the reward model in place, the agent can then be trained using standard RL algorithms. The goal is to optimize the agent’s policy to maximize the cumulative reward, as defined by the reward model. This process may involve iterative training, where the agent’s behavior is continuously refined based on new feedback.
Key Components of RLHF
Human-in-the-Loop (HITL)
Human-in-the-Loop (HITL) is a key component of RLHF, where humans are actively involved in the training process. This can involve providing feedback on the agent’s actions, correcting mistakes, or guiding the agent’s exploration. HITL ensures that the agent’s learning is aligned with human intentions and values.
Reward Shaping
Reward shaping involves designing the reward function to guide the agent’s learning more effectively. In RLHF, reward shaping is often based on human feedback, with the goal of encouraging behaviors that are aligned with human preferences. Reward shaping can be challenging, as it requires balancing short-term rewards with long-term goals and ensuring that the reward function does not lead to unintended behaviors.
Inverse Reinforcement Learning (IRL)
Inverse Reinforcement Learning (IRL) is a technique used in RLHF to infer the reward function from observed behavior. Instead of explicitly defining the reward function, IRL learns it by observing how humans or other agents behave in the environment. This approach is particularly useful in applications where the reward function is difficult to define explicitly, such as in complex decision-making tasks.
RLHF vs. Traditional RL
Advantages of RLHF
Alignment with Human Values: RLHF allows AI systems to learn behaviors that are more aligned with human values and preferences, leading to more ethical and responsible AI.
Flexibility: RLHF can be applied to a wide range of tasks, from natural language processing to robotics, making it a versatile approach for guiding AI behavior.
Improved Performance: By incorporating human feedback, RLHF can lead to better performance in tasks where the desired behavior is complex or difficult to define algorithmically.
Limitations of RLHF
Scalability: Collecting and processing human feedback at scale can be challenging, particularly in real-time applications.
Bias and Subjectivity: Human feedback is inherently subjective and can be influenced by biases, which can lead to challenges in ensuring that the feedback is representative and unbiased.
Complexity: RLHF introduces additional complexity into the RL process, particularly in terms of reward modeling and policy optimization.
Applications of RLHF
Natural Language Processing (NLP)
Language Model Fine-Tuning
RLHF has been widely used in fine-tuning large language models, such as OpenAI’s GPT series. By incorporating human feedback, these models can be trained to generate more coherent, contextually appropriate, and ethically aligned responses. This is particularly important in applications like chatbots, virtual assistants, and content generation, where the quality of the output is critical.
Dialogue Systems and Chatbots
In dialogue systems and chatbots, RLHF can be used to improve the quality of interactions by aligning the agent’s responses with human preferences. For example, RLHF can be used to train chatbots to provide more helpful, empathetic, and contextually relevant responses, leading to a better user experience.
Robotics
Human-Robot Interaction
In robotics, RLHF can be used to improve human-robot interaction by training robots to perform tasks in a way that is more aligned with human expectations. For example, RLHF can be used to train a robot to assist with household chores, ensuring that the robot’s actions are safe, efficient, and considerate of human preferences.
Autonomous Navigation
RLHF can also be applied to autonomous navigation, where the goal is to train robots or vehicles to navigate complex environments safely and efficiently. By incorporating human feedback, RLHF can help ensure that the robot’s navigation behavior is aligned with human safety standards and preferences.
Recommender Systems
Personalized Recommendations
In recommender systems, RLHF can be used to provide more personalized recommendations by incorporating user feedback into the training process. For example, RLHF can be used to train a recommendation algorithm to prioritize content that is more likely to be of interest to the user, based on their past behavior and preferences.
Feedback-Driven Content Curation
RLHF can also be used to improve content curation by incorporating user feedback into the training of the recommendation algorithm. This can help ensure that the content presented to users is not only relevant but also aligned with their values and preferences.
Healthcare
Personalized Treatment Plans
In healthcare, RLHF can be used to develop personalized treatment plans by incorporating patient feedback into the training of the AI system. For example, RLHF can be used to train an AI system to recommend treatment options that are more likely to be effective and acceptable to the patient, based on their medical history and preferences.
Medical Diagnosis Assistance
RLHF can also be applied to medical diagnosis assistance, where the goal is to train an AI system to provide accurate and reliable diagnostic recommendations. By incorporating feedback from medical professionals, RLHF can help ensure that the AI system’s recommendations are aligned with clinical best practices and patient needs.
Gaming and Simulation
AI Game Agents
In gaming, RLHF can be used to train AI game agents that are more challenging and engaging for players. By incorporating feedback from players, RLHF can help ensure that the AI agent’s behavior is aligned with the player’s expectations and preferences, leading to a more enjoyable gaming experience.
Training in Simulated Environments
RLHF can also be used to train AI agents in simulated environments, where the goal is to prepare the agent for real-world tasks. By incorporating human feedback, RLHF can help ensure that the agent’s behavior in the simulated environment is aligned with real-world requirements and constraints.

How is RLHF Used in the Field of Generative AI?
Generative AI refers to a class of artificial intelligence models designed to generate new content, such as text, images, audio, or video, that resembles human-created content. Reinforcement Learning from Human Feedback (RLHF) has emerged as a critical technique for improving the performance, safety, and alignment of generative AI systems. This section explores how RLHF is applied in generative AI, its benefits, and its challenges.
Overview of Generative AI
Generative AI models, such as language models (e.g., GPT, BERT), image generators (e.g., DALL·E, Stable Diffusion), and audio models (e.g., WaveNet, Jukebox), are trained to produce outputs that mimic human creativity. These models are typically trained on large datasets using unsupervised or self-supervised learning techniques. However, while they excel at generating coherent and realistic outputs, they often struggle with issues such as:
Lack of alignment with human intent: The model may generate outputs that are technically correct but not aligned with user expectations or ethical guidelines.
Bias and harmful content: Generative models can inadvertently produce biased, offensive, or harmful content due to biases in the training data.
Incoherence or inconsistency: The generated content may lack coherence or fail to maintain consistency over long sequences.
RLHF addresses these challenges by incorporating human feedback into the training process, ensuring that the model’s outputs are more aligned with human preferences, values, and ethical standards.
Applications of RLHF in Generative AI
Fine-Tuning Language Models
One of the most prominent applications of RLHF in generative AI is the fine-tuning of large language models (LLMs), such as OpenAI’s GPT series. Here’s how RLHF is used in this context:
Pre-training: The model is first pre-trained on a large corpus of text data using unsupervised learning. This gives the model a broad understanding of language but does not ensure alignment with specific user needs or ethical guidelines.
Supervised Fine-Tuning: The model is fine-tuned on a smaller dataset of human-labeled examples, where humans provide correct responses to specific prompts. This helps the model learn to generate more accurate and contextually appropriate outputs.
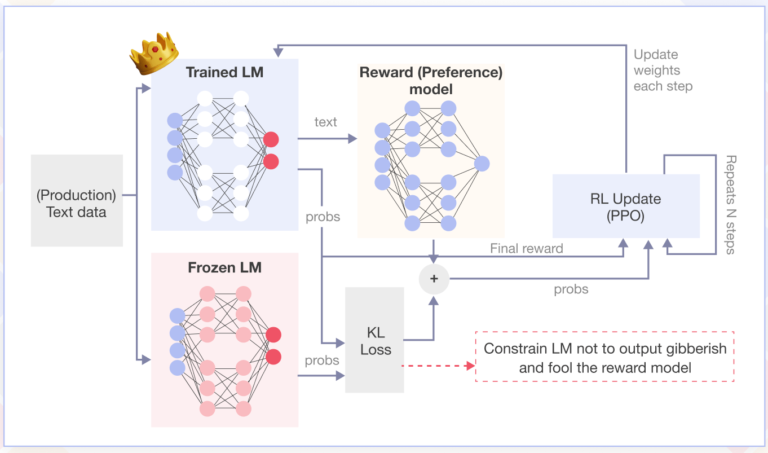
RLHF Phase: Human feedback is used to further refine the model. For example:
Humans rank or rate multiple model outputs based on quality, relevance, or alignment with ethical guidelines.
A reward model is trained to predict human preferences based on this feedback.
The language model is fine-tuned using reinforcement learning, with the reward model providing the reward signal.
This process ensures that the model generates outputs that are not only coherent but also aligned with human values and preferences.
Improving Dialogue Systems and Chatbots
RLHF is widely used to improve the performance of dialogue systems and chatbots. In these applications, the goal is to ensure that the chatbot’s responses are helpful, contextually appropriate, and aligned with user expectations. RLHF helps achieve this by:
Collecting feedback from users on the quality of the chatbot’s responses.
Using this feedback to train a reward model that guides the chatbot’s learning.
Fine-tuning the chatbot’s policy to maximize user satisfaction and engagement.
For example, OpenAI’s ChatGPT uses RLHF to ensure that its responses are not only accurate but also empathetic, safe, and aligned with user intent.
Content Moderation in Generative AI
Generative AI models, particularly those used in social media or content creation platforms, can produce harmful or inappropriate content. RLHF is used to train these models to avoid generating such content by:
Collecting feedback from human moderators on the appropriateness of generated outputs.
Training a reward model to penalize harmful or inappropriate content.
Fine-tuning the generative model to minimize the generation of such content.
This approach helps ensure that generative AI systems are safe and aligned with community guidelines.
Creative Applications: Art and Music Generation
RLHF is also being applied in creative domains, such as art and music generation. For example:
In image generation, RLHF can be used to fine-tune models like DALL·E or Stable Diffusion based on human feedback about the aesthetic quality, creativity, or relevance of generated images.
In music generation, RLHF can help models like Jukebox produce music that aligns with human preferences for melody, rhythm, and emotional tone.
By incorporating human feedback, these models can generate outputs that are not only technically impressive but also resonate with human audiences.
Implementing RLHF: A Step-by-Step Guide
Step 1: Define the Problem and Objectives
The first step in implementing RLHF is to clearly define the problem and objectives. This involves identifying the specific task or behavior that the agent needs to learn, as well as the desired outcomes. For example, in a dialogue system, the objective might be to train the agent to generate responses that are more contextually appropriate and aligned with user preferences.
Step 2: Collect Human Feedback
Designing Feedback Mechanisms
The next step is to design feedback mechanisms that will be used to collect human feedback. This could involve creating user interfaces for explicit feedback, designing experiments to gather implicit feedback, or setting up systems for comparative feedback. The key is to ensure that the feedback mechanisms are effective, scalable, and representative of the target user base.
Ensuring Quality and Diversity of Feedback
It is important to ensure that the feedback collected is of high quality and diverse, representing a wide range of perspectives and preferences. This may involve filtering out noisy or inconsistent feedback, as well as actively seeking feedback from a diverse group of users.
Step 3: Model the Reward Function
Reward Function Design
Once human feedback is collected, the next step is to model the reward function based on this feedback. This involves translating the feedback into a reward signal that the agent can use to optimize its behavior. The reward function should be designed to reflect human preferences and values, while also being computationally efficient.
Handling Noisy and Inconsistent Feedback
Human feedback can be noisy and inconsistent, which can pose challenges for reward modeling. Techniques such as regularization, smoothing, and outlier detection can be used to handle noisy feedback and ensure that the reward function is robust and reliable.
Step 4: Train the RL Agent
Choosing the Right RL Algorithm
The next step is to choose the right RL algorithm for training the agent. This will depend on the specific task, the complexity of the environment, and the nature of the feedback. Common RL algorithms used in RLHF include Q-learning, policy gradient methods, and actor-critic methods.
Balancing Exploration and Exploitation
During training, it is important to balance exploration and exploitation to ensure that the agent learns effectively. This may involve using techniques such as epsilon-greedy exploration, where the agent occasionally takes random actions to explore the environment, or using more sophisticated exploration strategies like Thompson sampling.
Step 5: Evaluate and Iterate
Metrics for Evaluation
Once the agent is trained, it is important to evaluate its performance using appropriate metrics. This could involve measuring the agent’s ability to achieve the desired outcomes, as well as assessing the quality of its behavior based on human feedback. Common metrics used in RLHF include reward maximization, alignment with human preferences, and safety.
Iterative Improvement
RLHF is an iterative process, and it is important to continuously refine the agent’s behavior based on new feedback. This may involve retraining the agent with updated feedback, adjusting the reward function, or fine-tuning the RL algorithm. The goal is to continuously improve the agent’s performance and alignment with human values.
Challenges and Ethical Considerations in RLHF
Bias in Human Feedback
Sources of Bias
Human feedback can be influenced by various sources of bias, including cultural differences, personal preferences, and cognitive biases. This can lead to challenges in ensuring that the feedback is representative and unbiased, particularly when the feedback is used to train models that will be deployed in diverse contexts.
Mitigating Bias
To mitigate bias in human feedback, it is important to actively seek feedback from a diverse group of users and to use techniques such as debiasing algorithms and fairness constraints. Additionally, it is important to continuously monitor and evaluate the agent’s behavior to ensure that it is not perpetuating or amplifying biases.
Ethical Concerns
Privacy and Data Security
Collecting and using human feedback raises important ethical concerns related to privacy and data security. It is important to ensure that user data is collected and used in a way that respects privacy and complies with relevant regulations, such as GDPR.
Autonomy and Control
RLHF also raises concerns related to autonomy and control, particularly in applications where the agent’s behavior has a significant impact on human lives. It is important to ensure that the agent’s behavior is transparent and that users have control over how their feedback is used.
Scalability and Efficiency
Handling Large-Scale Feedback
As RLHF is applied to larger and more complex tasks, scalability becomes a significant challenge. It is important to develop efficient algorithms and systems for collecting, processing, and using large-scale feedback, while also ensuring that the feedback is of high quality and representative.
Computational Costs
RLHF can be computationally expensive, particularly when training large models or using complex reward functions. It is important to optimize the training process to reduce computational costs, while also ensuring that the agent’s performance is not compromised.
Long-Term Impact and Unintended Consequences
Over-Optimization and Reward Hacking
One of the risks of RLHF is over-optimization, where the agent learns to maximize the reward function in ways that are not aligned with human intentions. This can lead to unintended consequences, such as reward hacking, where the agent finds loopholes in the reward function to achieve high rewards without actually performing the desired behavior.
Ensuring Alignment with Human Values
To ensure that the agent’s behavior is aligned with human values, it is important to continuously monitor and evaluate the agent’s behavior, and to update the reward function as needed. Additionally, it is important to involve a diverse group of stakeholders in the design and evaluation of the RLHF system to ensure that it reflects a broad range of perspectives and values.

Case Studies and Real-World Examples
OpenAI’s GPT Models and RLHF
Fine-Tuning GPT-3 with Human Feedback
OpenAI has used RLHF to fine-tune its GPT-3 language model, incorporating human feedback to improve the model’s ability to generate coherent, contextually appropriate, and ethically aligned responses. This has led to significant improvements in the model’s performance, particularly in applications like chatbots and virtual assistants.
Lessons Learned and Future Directions
The use of RLHF in fine-tuning GPT-3 has provided valuable insights into the challenges and opportunities of incorporating human feedback into AI training. Key lessons include the importance of diverse and representative feedback, the need for robust reward modeling, and the potential for RLHF to improve the alignment of AI systems with human values.
DeepMind’s AlphaStar and RLHF
Training AlphaStar with Human Feedback
DeepMind has used RLHF to train its AlphaStar AI, which is capable of playing the complex real-time strategy game StarCraft II at a superhuman level. By incorporating feedback from human players, AlphaStar was able to learn strategies and behaviors that are more aligned with human playstyles, leading to a more engaging and challenging gaming experience.
Implications for AI in Gaming
The success of AlphaStar demonstrates the potential of RLHF in gaming, particularly in training AI agents that can compete with or assist human players. This has important implications for the future of AI in gaming, including the development of more sophisticated and adaptive game AI, as well as the potential for AI to enhance the gaming experience.
RLHF in Autonomous Vehicles
Human Feedback for Safe Navigation
RLHF has been applied to the development of autonomous vehicles, where the goal is to train the vehicle to navigate safely and efficiently in complex environments. By incorporating feedback from human drivers, RLHF can help ensure that the vehicle’s behavior is aligned with human safety standards and preferences.
Challenges in Real-World Deployment
The deployment of RLHF in autonomous vehicles presents significant challenges, particularly in terms of scalability, safety, and regulatory compliance. It is important to ensure that the vehicle’s behavior is robust and reliable, and that it can handle a wide range of real-world scenarios.
RLHF in Social Media Platforms
Feedback-Driven Content Moderation
RLHF has been used in social media platforms to improve content moderation by incorporating user feedback into the training of the moderation algorithm. This can help ensure that the content presented to users is not only relevant but also aligned with community standards and values.
Ethical Implications of Algorithmic Control
The use of RLHF in content moderation raises important ethical concerns related to algorithmic control and freedom of expression. It is important to ensure that the moderation algorithm is transparent, fair, and accountable, and that it does not inadvertently suppress legitimate content or amplify harmful content.
Future Directions and Research Opportunities
Improving Feedback Mechanisms
Active Learning and Adaptive Feedback
One area of future research is the development of more sophisticated feedback mechanisms, such as active learning and adaptive feedback. Active learning involves the agent actively seeking feedback on the most informative or uncertain aspects of its behavior, while adaptive feedback involves adjusting the feedback process based on the agent’s performance and learning progress.
Crowdsourcing and Distributed Feedback
Another area of research is the use of crowdsourcing and distributed feedback to collect large-scale, diverse feedback from a wide range of users. This can help ensure that the feedback is representative and unbiased, while also improving the scalability and efficiency of the RLHF process.
Enhancing Reward Modeling
Multi-Objective Reward Functions
Future research could also focus on the development of multi-objective reward functions, which allow the agent to optimize for multiple, potentially conflicting objectives. This can help ensure that the agent’s behavior is aligned with a broader range of human values and preferences.
Incorporating Long-Term Goals
Another area of research is the incorporation of long-term goals into the reward function. This can help ensure that the agent’s behavior is not only aligned with short-term rewards but also with long-term objectives, such as sustainability, fairness, and ethical considerations.
Scaling RLHF for Complex Environments
Transfer Learning and Generalization
As RLHF is applied to more complex environments, it is important to develop techniques for transfer learning and generalization, allowing the agent to apply what it has learned in one context to new, unseen contexts. This can help improve the scalability and adaptability of RLHF systems.
Combining RLHF with Other Learning Paradigms
Future research could also explore the combination of RLHF with other learning paradigms, such as unsupervised learning, self-supervised learning, and meta-learning. This can help improve the efficiency and effectiveness of the RLHF process, particularly in complex and dynamic environments.
Ethical AI and Value Alignment
Ensuring Fairness and Transparency
One of the key challenges in RLHF is ensuring that the agent’s behavior is fair and transparent. Future research could focus on developing techniques for fairness-aware learning, where the agent’s behavior is explicitly optimized to avoid bias and discrimination, as well as techniques for explainable AI, where the agent’s decisions are transparent and interpretable.
Aligning AI with Human Values
Finally, future research could focus on the broader challenge of aligning AI with human values. This involves not only ensuring that the agent’s behavior is aligned with human preferences but also that it reflects a broader range of ethical considerations, such as justice, autonomy, and well-being. This is a complex and multifaceted challenge that will require interdisciplinary collaboration and ongoing research.
Conclusion
Recap of Key Points
Reinforcement Learning from Human Feedback (RLHF) is a powerful approach that combines traditional RL techniques with human feedback to guide the learning process. By incorporating human feedback, RLHF allows AI systems to learn behaviors that are more aligned with human values, preferences, and ethical considerations. This approach has been successfully applied in a wide range of applications, from natural language processing and robotics to healthcare and gaming.
The Future of RLHF in AI
As AI systems become more integrated into our daily lives, the importance of RLHF will only continue to grow. Future research and development in RLHF will focus on improving feedback mechanisms, enhancing reward modeling, scaling RLHF for complex environments, and ensuring ethical AI and value alignment. These efforts will help ensure that AI systems are not only intelligent but also responsible, trustworthy, and aligned with human values.
Final Thoughts and Recommendations
RLHF represents a promising pathway to achieving more ethical and responsible AI. However, it also presents significant challenges, particularly in terms of scalability, bias, and ethical considerations. To fully realize the potential of RLHF, it is important to approach these challenges with a multidisciplinary perspective, involving experts from AI, ethics, psychology, and other fields. By working together, we can develop AI systems that are not only powerful but also aligned with the best of human values and intentions.
// Frequently Asked Questions (FAQs)
RLHF is a machine learning approach that combines traditional reinforcement learning (RL) with human feedback to guide the learning process. Instead of relying solely on predefined reward functions, RLHF uses human feedback to shape the reward signal, enabling the AI system to learn behaviors that are more aligned with human values and preferences.
In traditional RL, the agent learns by maximizing a predefined reward function. In RLHF, the reward function is derived from human feedback, making the learning process more flexible and aligned with human intentions. RLHF is particularly useful in tasks where the desired behavior is complex, subjective, or difficult to define algorithmically.
Human feedback is crucial because it provides a way to incorporate human values, preferences, and ethical considerations into the AI system's learning process. This is especially important in applications like natural language processing, robotics, and generative AI, where the stakes are high, and the impact on human lives is significant.
RLHF is used in generative AI to fine-tune models like language models, image generators, and music generators. Human feedback is collected to guide the model's learning, ensuring that the generated outputs are aligned with human preferences, ethical guidelines, and contextual appropriateness. For example, RLHF is used to improve the quality of chatbot responses, reduce harmful content, and enhance creative outputs like art and music.
The benefits include:
Improved alignment with human values and preferences.
Enhanced safety and reliability by reducing harmful or biased outputs.
Better user experience through more relevant and coherent outputs.
Adaptability to diverse contexts and user needs.
Challenges include:
Scalability of collecting and processing human feedback.
Subjectivity and bias in human feedback.
Risk of reward hacking, where the model optimizes for rewards without truly aligning with human intent.
Ethical concerns related to privacy, consent, and data security.
The key components of RLHF include:
Data Collection: Gathering human feedback through explicit ratings, implicit behavior signals, or comparative judgments.
Reward Modeling: Translating human feedback into a reward signal that the agent can use to optimize its behavior.
Policy Optimization: Training the agent using reinforcement learning algorithms to maximize the reward signal.
Reward modeling involves translating human feedback into a reward signal that the agent can use to optimize its behavior. The reward model must accurately reflect human preferences and values while being computationally efficient. It is a critical component of RLHF, as it bridges the gap between human feedback and the agent's learning process.
RLHF uses techniques like regularization, smoothing, and outlier detection to handle noisy or inconsistent feedback. Additionally, the feedback collection process is designed to ensure diversity and quality, reducing the impact of noise and inconsistencies on the reward model.
RLHF will play a critical role in ensuring that AI systems are not only intelligent but also aligned with human values and ethical considerations. As AI becomes more integrated into our daily lives, RLHF will help bridge the gap between machine intelligence and human intent, enabling the development of responsible and trustworthy AI systems.